
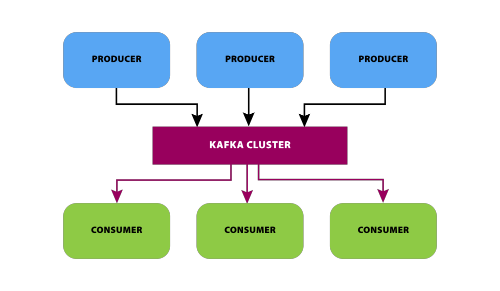

Navigating Compatibility: A Guide to Kafka Broker API Versions

Apache Kafka, renowned for its distributed streaming capabilities, relies on a well-defined set of APIs to facilitate communication between clients and brokers. Understanding the compatibility between Kafka clients and broker API versions is crucial for maintaining a stable and efficient streaming environment. In this blog post, we’ll delve into the realm of Kafka Broker API … Read more



















