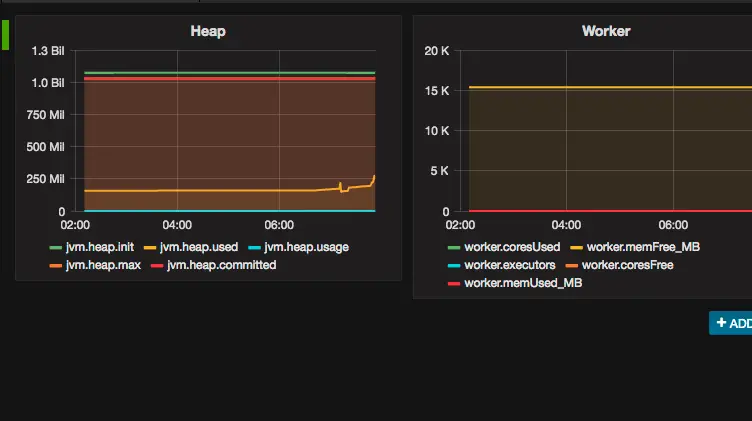
Spark Performance Monitoring Tools – A List of Options

Which Spark performance monitoring tools are available to monitor the performance of your Spark cluster? In this tutorial, we’ll find out. But, before we address this question, I assume you already know Spark includes monitoring through the Spark UI? And, in addition, you know Spark includes support for monitoring and performance debugging through the Spark … Read more