
Kafka Consumer Groups are the way to horizontally scale out event consumption from Kafka topics… with failover resiliency. “With failover resiliency” you say!? That sounds interesting. Well, hold on, let’s leave out the resiliency part for now and just focus on scaling out. We’ll come back to resiliency later.
When designing for horizontal scale-out, let’s assume you would like more than one Kafka Consumer to read in parallel with another. Why? Maybe you are trying to answer the question “How can we consume and process more quickly?”
Table of Contents
- Kafka Topic Fundamentals
- Kafka Consumer Group Essentials
- How Kafka Consumer Group Works Rules
- Kafka Consumer Group Example
- Kafka Consumer Groups Examples Pictures and Demo
- Why Kafka Consumer Groups?
- References
Now, we’ve covered Kafka Consumers in a previous tutorial, so you may be wondering, how are Kafka Consumer Groups the same or different? Well, don’t you wonder too long my Internet buddy, because you are about to find out, right here and right now. Ready!? Of course, you are ready, because you can read. Also, if you like videos, there’s an example of Kafka Consumer Groups waiting for you below too. The video should cover all the things described here. Are you ready for a good time? That should be a song.
Anyhow, first some quick history and assumption checking…
Like many things in Kafka’s past, Kafka Consumer Groups use to have a Zookeeper dependency. But starting in 0.9, the Zookeeper dependency was removed. So, if you are revisiting Kafka Consumer Groups from previous experience, this may be news to you. There’s a link in the Reference section below which you might want to check out if you are interested in learning more about the dependency history.
Kafka Topic Fundamentals
First off, in order to understand Kafka Consumer Groups, let’s confirm our understanding of how Kafka topics are constructed. Recall that Kafka topics consist of one or more partitions. There is even a configuration setting for the default number of partitions created for each topic in the server.properties files called `num.partitions` which is by default set to 1. More partitions allow more parallelism. Or, put another way and as we shall see shortly, allow more than one Consumer to read from the topic.
To see partitions in topics visually, consider the following diagrams.
A Kafka topic with a single partition looks like this
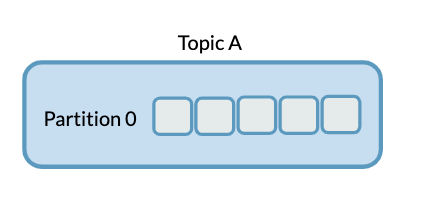
A Kafka Topic with four partitions looks like this
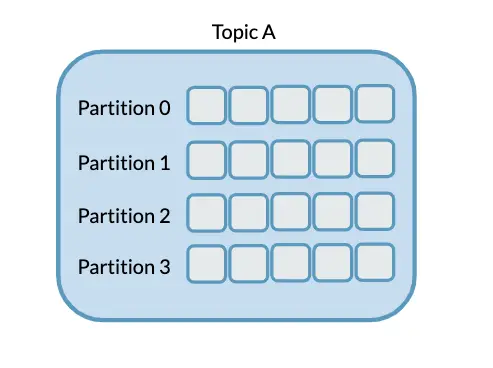
And note, we are purposely not distinguishing whether or not the topic is being written from a Producer with particular keys.
Kafka Consumer Group Essentials
Now, if we visualize Consumers working independently (without Consumer Groups) compared to working in tandem in a Consumer Group, it can look like the following example diagrams.
Without Consumer Groups
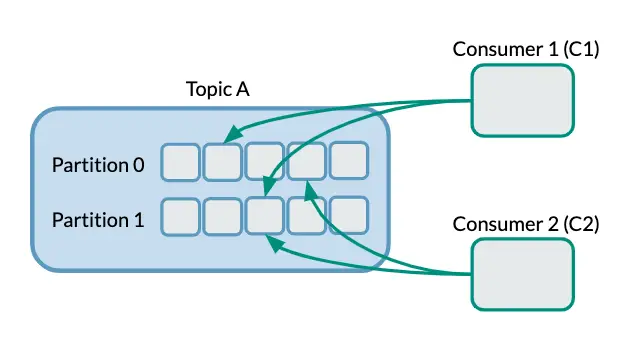
With Consumer Groups
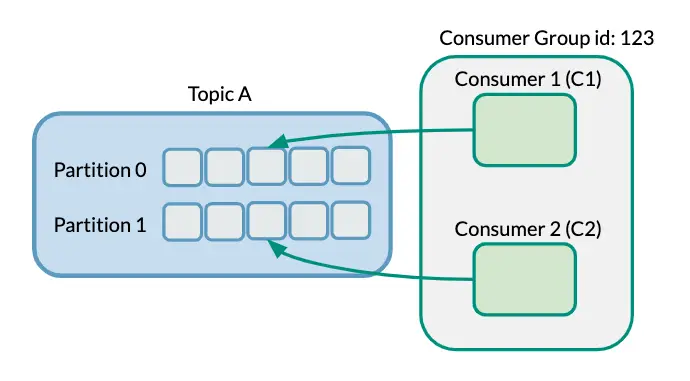
How Kafka Consumer Group Works Rules
To recap, it may be helpful to remember the following rules:
- Each partition in a topic will be consumed by exactly one Consumer in a Consumer Group. In other words, max of one Consumer for each Partition. Multiple Consumers in the same Group cannot read from the same partition.
- Now, one Consumer may consume from more than one partition, if there are fewer Consumers in a Consumer Group than there are topic partitions; i.e. 6 partitions with 3 Consumers.
- If you like deploying with efficient use of resources (and I highly suspect you do), then the number of consumers in a Consumer Group should equal or less than partitions, but you may also want a standby as described in this post’s accompanying screencast.
A quick comment on that last bullet point– here’s the “resiliency” bit. Deploying more Consumers than partitions might be redundancy purposes and avoiding a single point of failure; what happens if my one consumer goes down!? As we’ll see in the screencast, an idle Consumer in a Consumer Group will pick up the processing if another Consumer goes down.
If bullet points are not your thing, then here’s another way to describe the first two bullet points. Let’s say you N number of consumers, well then you should have at least N number of partitions in the topic. Or, put a different way, if the number of consumers is greater than the number of partitions, you may not be getting it because any additional consumers beyond the number of partitions will be sitting there idle. We show an example of this in the video later.
Kafka Consumer Group Example
Alright, enough is enough, right. Let’s get to some code. In the Consumer Group screencast below, call me crazy, but we are going to use code from the previous examples of Kafka Consumer and Kafka Producer.
We are going to configure IntelliJ to allow us to run multiple instances of the Kafka Consumer. This will allow us to run multiple Kafka Consumers in the Consumer Group and simplify the concepts described here. I show how to configure this in IntelliJ in the screencast if you are interested.
And again, the source code may be downloaded from https://github.com/tmcgrath/kafka-examples
Kafka Consumer Groups Examples Pictures and Demo
In the following screencast, let’s cover Kafka Consumer Groups with diagrams and then run through a demo.
The link to the Github repo used in the demos is available below. Here are the bullet points of running the demos yourself
- Kafka and Zookeeper are running. Run list topics to show everything running as expected.
- Create an example topic with 2 partitions with
bin/kafka-topics.sh --create --bootstrap-server localhost:9092 --replication-factor 1 --partitions 2 --topic example-topic Run Consumer 1 (show how to run more than one instance in IntelliJ), Run Consumer 2 (after editing) with different group id and show the output. Run Producer. Both consume everything and notice how there is no sequential ordering because Consumers are consuming from both partitions. Ordering is on a per partition basis.- What happens if we change these Consumers to be part of the same group? Stop Consumers and producer, set new Group id, rerun both, which shows round robin results because the key is unique for each message.
- What happens if we add a third consumer? Fire up a third consumer and show how it’s idle, kill one consumer and then re-run the producer to show how consumer 3 is now engaged (note:
session.timeout.msand `heartbeat.interval.ms`) - Stop all running consumers and producers. Restart consumers (notice even though earliest it’s reading… this because already read and stored in `__consumer_offsets`, run Producer with key “red” vs “blue” vs. “green” and now highlight how each consumer goes to each partition in order. Run a few times. Note: murmur2 hash on key and the run mod 2 (based on the number of partitions.)
- Repeat the previous step but use a topic with 3 partitions
- Repeat the previous step but use a new topic with 4 partitions
Why Kafka Consumer Groups?
In distributed computing frameworks, the capability to pool resources to work in collaboration isn’t new anymore, right? In other words, you may be asking “why Kafka Consumer Groups?” What makes Kafka Consumer Groups so special? Good question, thanks for asking.
To me, the first reason is how the pooling of resources is coordinated amongst the “workers”. I put “workers” in quotes because the naming may be different between frameworks. But in this case, “workers” is essentially an individual process performing work in conjunction with other processes in a group or pool. Multiple processes working together to “scale out”. In Kafka Consumer Groups, this worker is called a Consumer.
The coordination of Consumers in Kafka Consumer Groups does NOT require an external resource manager such as YARN. The capability is built into Kafka already. This is an attractive differentiator for horizontal scaling with Kafka Consumer Groups. Put another way, if you want to scale out with an alternative distributed cluster framework, you’re going to need to run another cluster of some kind and that may add unneeded complexity.
Now, another reason to invest in understanding Kafka Consumer Groups is if you are using other components in the Kafka ecosystem such as Kafka Connect or Kafka Streams. Both Kafka Connect and Kafka Streams utilize Kafka Consumer Groups behind the scenes, but we’ll save that for another time. Or if you have any specific questions or comments, let me know in the comments.
References
Kafka examples source code used in this post
Introducing the Kafka Consumer: Getting Started with the New Apache Kafka 0.9 Consumer Client
Kafka Consumer Group Operations from CLI
Post image https://pixabay.com/users/Kanenori-4749850