
Performing Kafka Streams Joins presents interesting design options when implementing streaming processor architecture patterns.
There are numerous applicable scenarios, but let’s consider an application might need to access multiple database tables or REST APIs in order to enrich a topic’s event record with context information. For example, perhaps we could augment records in a topic with sensor event data with location and temperature with the most current weather information for the location.
Furthermore, let’s say we require these weather lookups based on a sensor’s location to have extremely low processing latency which we cannot achieve with a database or REST API lookup. In this case, we may wish to leverage the Kafka Streams API to perform joins of such topics (sensor events and weather data events), rather than requiring lookups to remote databases or REST APIs. This could result in improved processing latency. (If not entirely obvious, this previous example assumes we are piping sensor and weather events into Kafka topics)
Table of Contents
- Kafka Streams Joins Operators
- Kafka Streams Joins Code Overview
- How to run the Kafka join examples?
- Kafka Joins Examples Conclusion
In this Kafka Streams Joins examples tutorial, we’ll create and review the sample code of various types of Kafka joins. In addition, let’s demonstrate how to run each example. The intention is a deeper dive into Kafka Streams joins to highlight possibilities for your use cases. For more information on stream processors in general, see the Stream Processors page.
These examples below are in Scala, but the Java version is also available at https://github.com/tmcgrath/kafka-streams-java.
Kafka Streams Joins Operators
When going through the Kafka Stream join examples below, it may be helpful to start with a visual representation of expected results join operands.
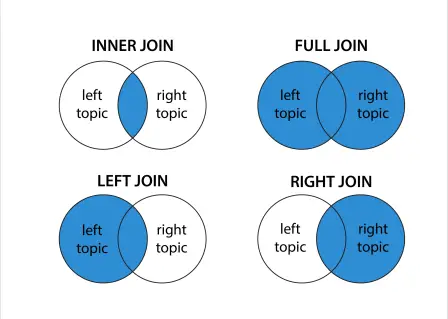
When we go through examples of Kafka joins, it may be helpful to keep this above diagram in mind. The color blue represents are expected results when performing the Kafka based joins.
Kafka Streams Joins Code Overview
We can implement Kafka joins in different ways. In the following examples, we’ll cover the Kafka Streams DSL perspective. From this approach, we’ll use the DSL for abstractions such as `KTable`, `KStream`, and `GlobalKTable`. We’ll cover various usage examples of these abstractions, but it’s important to note regardless of abstraction, joining streams involves :
- Specifying at least two input streams which are read from Kafka topics
- Performing transformations on the joined streams to produce results
- Writing the results back to Kafka topics
In essence, we will be creating miniature stream processing applications for each one of the join examples.
But first, how should we think about our choices of `KTable` vs `KStream` vs `GlobalKTable`?
`KTable` represents each data record as an upsert. If an existing key in the stream exists, it will be updated. If the key does not exist it will be inserted. For those of you coming from relational databases, I like to think of `KTable` as a form of a reference table. In my experience, the use of reference tables was concerned with using the latest values for a particular key rather than the entire history of a particular key. The value of a reference table was looking up the most recent value of a particular key in a table, rather than all the values of a particular key.
`KStream` on the other hand is designed for when you are concerned with the entire history of data events for particular keys. This is often referred to as each data record as being considered an insert (rather than an update or upsert in `KTable`). For example, KStream would be utilized to process each sensor temperature readings in order to produce an average temperature over a period of time. All the historical records are required to produce a reasonable average. This is in contrast to `KTable` where you might wish to know the most recent average temperatures of all sensors in a particular region. You wouldn’t use a `KTable` to calculate an average because KTable would always return the most recent individual temperature and not concerned with each individual event like `KStream`.
`GlobalKTable`, as the name implies, is a form of `KTable`. Unlike a regular `KTable` which will represent 1 partition from the topic of which it is being composed, `GlobalKTable`, on the other hand, accounts for all partitions in the underlying topic. As you can imagine, this has advantages but also performance-related considerations as well. Performance-related considerations include increased storage and increased network transmission requirements. Other benefits of `GlobalKTable` include no requirement for co-partitioning for joins, the ability to broadcast to all running instances of an application, and more join operations which we won’t cover in any detail here because of the introductory nature of this tutorial.
We do not cover co-partitioning in this tutorial but let me know if you’d like to explore further.
Types of Kafka Streams Joins
Keep in mind there are essentially two types of joins: windowed and non-windowed. Windowing allows us to control how to group records that have the same key.
In joins, a windowing state store is used to retain all the records within a defined window boundary. Old records in the state store are purged after a defined retention period. The default window retention period is one day. I’ll add relevant windowing where applicable in the join examples below.
Kafka Streams Join Examples
Before we get into the Kafka Streams Join source code examples, I’d like to show a quick screencast of running the examples to help set some overall context and put you in a position to succeed. As you’ll see, the examples are in Scala, but let me know if you’d like to see them converted to Java. Let me know.
As you see in the screencast, we’re going to run all the Kafka Streams Joins examples through Scala tests. If you want some background on this approach, it may be helpful to check out the previous Kafka Streams Testing post.
Code Examples
Let’s start with 3 examples of `KTable` to `KTable` joins. These examples and other examples of Kafka Joins are contained in the `com.supergloo.KafkaStreamsJoins` class. (All source code is available for download. See link to it in the Reference section below and Screencast above for further reference.)
Each of the `KTable` to `KTable` join examples are within functions starting with the name `kTableToKTable`. For example, an inner join example is within the `kTableToKTableJoin` function
def kTableToKTableJoin(inputTopic1: String,
inputTopic2: String,
storeName: String): Topology = {
val builder: StreamsBuilder = new StreamsBuilder
val userRegions: KTable[String, String] = builder.table(inputTopic1)
val regionMetrics: KTable[String, Long] = builder.table(inputTopic2)
userRegions.join(regionMetrics,
Materialized.as(storeName))((regionValue, metricValue) => regionValue + "/" + metricValue)
builder.build()
}What’s going on in the code above?
Using a `StreamBuilder` we construct two `KTable` and perform the inner join. In the args we are providing to `join` function, we are providing a specific instance of `StateStore` in `Materialzed.as(storedName)`. In essence, this `StateStore` is another `KTable` which is based on a Kafka topic. I find it helps when I attempt to simplify the constructs behind the API. In this case, we’re simply joining two topics based on keys and particular moments in time (message ordering in the topic). The results of this join are stored to another Kafka topic for a period of time. Finally, in the last portion of the call
((regionValue, metricValue) => regionValue + "/" + metricValue)we’re providing an implementation of what to do with the values of each topic based on the join of keys. If this is confusing, it will make sense when you see the results we are testing for next. (Also, to really drive it home, try changing “/” to “-” for example and re-run the tests to see the failures.)
How to run the Kafka join examples?
To run the Kafka join examples, check out the `com.supergloo.KafkaStreamsJoinsSpec` test class as shown in the Screencast above. Running this class will run all of the Kafka join examples. For example, the following test will run this inner join test described above.
// ------- KTable to KTable Joins ------------ //
"KTable to KTable Inner join" should "save expected results to state store" in {
val driver = new TopologyTestDriver(
KafkaStreamsJoins.kTableToKTableJoin(inputTopicOne, inputTopicTwo, stateStore),
config
)
driver.pipeInput(recordFactory.create(inputTopicOne, userRegions))
driver.pipeInput(recordFactoryTwo.create(inputTopicTwo, sensorMetric))
// Perform tests
val store: KeyValueStore[String, String] = driver.getKeyValueStore(stateStore)
store.get("sensor-1") shouldBe "MN/99"
store.get("sensor-3-in-topic-one") shouldBe null
store.get("sensor-99-in-topic-two") shouldBe null
driver.close()
}The expected results specific to Kafka Joins will be in the tests
store.get("sensor-1") shouldBe "MN/99"
store.get("sensor-3-in-topic-one") shouldBe null
store.get("sensor-99-in-topic-two") shouldBe nullPay attention to how these tests differ from the other `KTable` to `KTable` join tests later in the test code.
Windowing note: As you might expect, `KTable` to `KTable` are non-windowed because of the nature of `KTable` where only the most recent keys are considered.
Next, let’s move on to `KStream` to `KTable` join examples. Following the overall code organization of join implementations and test examples described above, we can find three examples of these joins in functions starting with the name “kStreamToKTable” in `KafkaStreamsJoins`. Similarly, we can find examples of how to run the examples and differences in their tests in the `KafkaStreamsJoinsSpec` class.
As you’ll see in the implementation of the `KStream` to `KTable` examples, the API use is slightly different. For example, in the inner join example
val userRegions: KTable[String, String] = builder.table(inputTopic1)
val regionMetrics: KStream[String, Long] = builder.stream(inputTopic2)
regionMetrics.join(userRegions){(regionValue, metricValue) =>
regionValue + "/" + metricValue
}.to(outputTopicName)
val outputTopic: KTable[String, String] =
builder.table(
outputTopicName,
Materialized.as(storeName)
)In this example above, we don’t have the option to provide a `StateStore` in the join. So, instead, we use `to` function to pipe results to a new topic directly. Then, we customize the `StateStore` by creating a `KTable` with the previously mentioned topic, so we can reference in the tests.
When moving to the `KStream` to `KStream` examples with a function name starting with “kStreamToKStream”, notice we need to provide a `JoinWindow` now. For example
regionMetrics.join(userRegions)(
((regionValue, metricValue) => regionValue + "/" + metricValue),
JoinWindows.of(Duration.ofMinutes(5L))
).to(outputTopicName)The final two examples are `KStream` to `GlobalKTable` joins. Again, the code is similar, but key differences include how to create a GlobalKTable and the `join` function signature as seen in the following.
val userRegions: GlobalKTable[String, String] = builder.globalTable(inputTopic1)
val regionMetrics: KStream[String, Long] = builder.stream(inputTopic2)
regionMetrics.join(userRegions)(
(lk, rk) => lk,
((regionValue, metricValue) => regionValue + "/" + metricValue)
).to(outputTopicName)Constructing a `GlobalKTable` is simple enough that it doesn’t require elaboration.
The `join` function signature changes to require a keyValueMapper: `(lk, rk) => lk` This keyValueMapper is a function used to map the key, value pair from the KStream to the key of the `GlobalKTable`. In this implementation, nothing fancy. We simply want the key of the `KStream` (represented as “lk), to match the key of the `GlobalKTable`.
As you might expect based on the aforementioned description of `KTable` vs `GlobalKTable`, the tests in `KStream` to `GlobalKTable` joins are nearly identical to `KStream` to `KTable` examples.
Kafka Joins Examples Conclusion
Hopefully, you found these Kafka join examples helpful and useful. If you have any questions or even better, suggestions on how to improve, please let me know.
Noteworthy
As shown in the screencast above, the path is not smooth when a failed test occurs. If you run a test which fails and then you attempt to rerun tests again, an Exception occurs and none of the tests pass.
The Exception is
org.apache.kafka.streams.errors.LockException: task [0_0] Failed to lock the state directory for task 0_0
The only way I’ve found to resolve is `rm -rf /tmp/kafka-streams/testing/0_0/`
This experience happens when running tests in both IntelliJ and SBT REPL.
Let me know any suggestions to resolve.
References
- My Kafka Streams Github repo with all source code described above (Java version: https://github.com/tmcgrath/kafka-streams-java)
- Streaming Architectures
- Kafka Documentation on Joining
- Kafka Tutorials
Kafka Streams Joins Examples image credit: https://pixabay.com/en/network-networking-rope-connection-1246209/
I have two kafka streams. I need to merge those streams using KStreams and then push it to another queue using java. Let me know how to do in java as I dont understand Scala
I want to join two topic from rdbms (employees , department) how can we join them for employee concering department
Hi , Would like to see in Java as I am not familiar with Scala . Interested in reading stream data form two topics
I would like to see these codes in Java as well.
Hi Priya and Harshini,
Java examples now available at https://github.com/tmcgrath/kafka-streams-java I’m interested in your feedback on this Java version… do you have any questions or recommendations?
The issue with your test is that you are not closing the driver when an scenario fails. This try/finally does the trick:
“`
// ——- KStream to KTable Joins ———— //
“KStream to KTable join” should “save expected results to state store” in {
val driver = new TopologyTestDriver(
KafkaStreamsJoins.kStreamToKTableJoin(inputTopicOne,
inputTopicTwo,
outputTopic, stateStore),
config
)
try {
driver.pipeInput(recordFactory.create(inputTopicOne, userRegions))
driver.pipeInput(recordFactoryTwo.create(inputTopicTwo, sensorMetric))
// Perform tests
val store: KeyValueStore[String, String] = driver.getKeyValueStore(stateStore)
store.get(“sensor-1”) shouldBe “99-MN” // v,k compared with above
store.get(“sensor-3-in-topic-one”) shouldBe null
store.get(“sensor-99-in-topic-two”) shouldBe null
store.get(“sensor-100-in-topic-two”) shouldBe null
} finally {
driver.close()
}
}
“`
As an alternative, you could also create a function that wraps the creation of the driver and cleans it up after the test
PS: I really liked your tutorials and I took the liberty to create a PR to update it to the latest Scala, SBT, and Kafka Streams versions https://github.com/tmcgrath/kafka-streams/pull/1