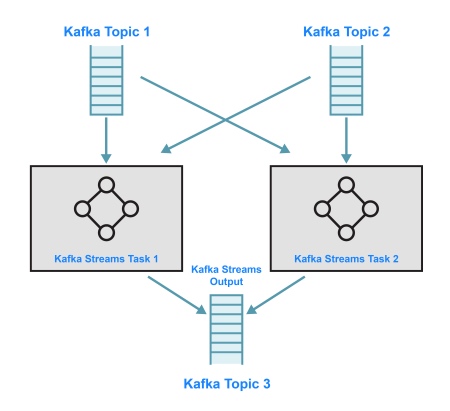

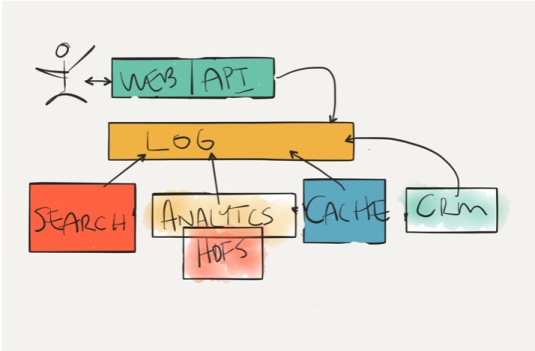
GlobalKTable vs KTable in Kafka Streams

Kafka Streams presents two options for materialized views in the forms of GlobalKTable vs KTables. We will describe the meaning of “materialized views” in a moment, but for now, let’s just agree there are pros and cons to GlobalKTable vs KTables. GlobalKTable vs. KTable Three Essential Factors The essential three factors in your decision of … Read more



