
Kafka Streams presents two options for materialized views in the forms of GlobalKTable vs KTables. We will describe the meaning of “materialized views” in a moment, but for now, let’s just agree there are pros and cons to GlobalKTable vs KTables.
Table of Contents
GlobalKTable vs. KTable Three Essential Factors
The essential three factors in your decision of when to use a GlobalKTable vs KTable will come down to 1) the number of nodes in your Kafka Streams application, 2) the number of partitions in your underlying topics, and 3) how you plan to join streams. For the last point on joins, in particular, you will find the choice of GlobalKTable vs KTable most interesting when you are designing and/or implementing Kafka Streams Joins when deployed across multiple nodes using topics having multiple partitions.
To help me understand this further and hopefully you as well, let’s explore GlobalKTable and KTables a bit more. Also, if the idea of “materialized view” is not clear to you, I think this post will help as well.
Let’s start with “Why KTable?”
KTable is an abstraction on a Kafka topic that can represent the latest state of a key/value pair. The underlying Kafka topic is likely enabled with log compaction. When I was first learning about KTables, the idea of UPSERTS immediately came to mind. Why? Well, the processing characteristics when attempting inserts or updates are familiar to upsert capable systems. For example, an attempt to append a key/value pair without an existing key in a KTable will result in an INSERT while an attempt to append a key/value pair with an existing key will result in an UPDATE.
KTable Example
For a simple example of a “materialized view” through KTables, consider an event arriving at the KTable with a key tommy and value of 3. If the tommykey does not exist in the KTable, it will be appended as an INSERT. On the other hand, when a subsequent event with a key of tommy arrives, the existing tommy key event will be updated. If the next tommy event has a value of 2, the KTable value for the tommy key will be 2.
Another key takeaway is the update is a simple replace and not a calculation of any sort. For example, the values of 3 and 2 do not result in a sum of 5.
KTable vs GlobalKTable Considerations
That’s great and simple to understand in isolation. But, we need to take it further in order to understand why KTable vs GlobalKTable? For that, we need to explore two more constructs before we get to the results.
The first construct involves the effect of operating Kafka Streams applications across multiple nodes with topics containing multiple partitions.
The second construct involves the ramifications of KTables with multiple underlying topic partitions and multiple Kafka Streams nodes when performing JOINS with other event streams.
Let’s start with KTables operations and then move to joins.
Let’s consider a Kafka Streams application deployed across three nodes with an application.id of ABC. These three Kafka Streams nodes are interacting with a Kafka Cluster with 3 Broker nodes. That keeps it simple right?
Now, let’s assume a KTable with an underlying topic that contains 3 partitions. On any node running your Kafka Streams application, this example KTable will only be populated with 1 partition worth of data. To illustrate this point, the key/value pair with the tommy key may or may not be present in your KTable.
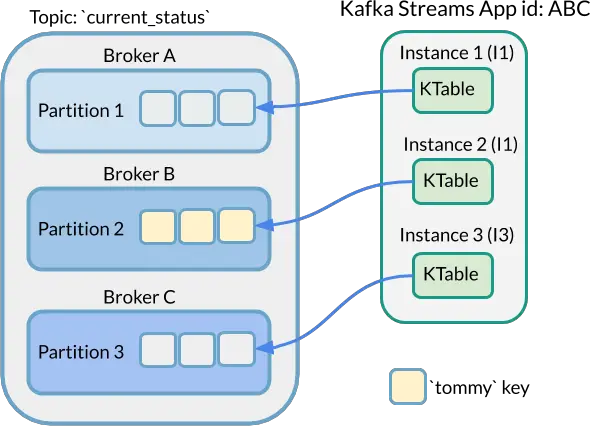
This shouldn’t come as shock when you consider how Kafka Streams and Kafka Connect often leverage the capabilities found in Producer and Consumer Kafka APIs. This 3 node, 3 partitions KTable example with the tommy key event is only present is similar to how Consumers will attach to 1-to-1 to particular partitions when configured in a Kafka Consumer Group.
Ok, so tommyis present in one KTable on a particular Kafka Streams node. So what? What’s the big deal? Let’s cover that next when we consider the mechanics of performing join operations. First, let’s setup our example.
KTable and KStream Join Example
Let’s assume we have a stream of data which represents tommy’s location. Perhaps the key/value pair is key = tommy and value = {longitude: 68.9063° W, latitude: 41.8101 S}. Now, imagine this stream of tommy’s location is arriving every 10 minutes or so landing in a KStream with an underlying topic with 6 partitions. Let’s call this stream the locations stream.
At this point, we have a KTable called tommy key with a materialized view value of 25. Maybe this is tommy’s current age or his jersey number or his favorite number. It doesn’t really matter. But, let’s call this KTable current_status.
What happens if we want to join locations with current_statusin this example? Should be simple right? The tommy keys align for performing the joins, but is it that simple? (hint: remember the 3 Kafka Streams app nodes interacting with a Kafka Cluster with 3 brokers where there are a different number of partitions in the underlying topics of both locationsKStream and the current_status KTable.)
Answer: there’s a chance the join will fail. Why? Because the Kafka Streams node performing the join may not have the tommy key from both locationsand current_status as shown in the following diagram.
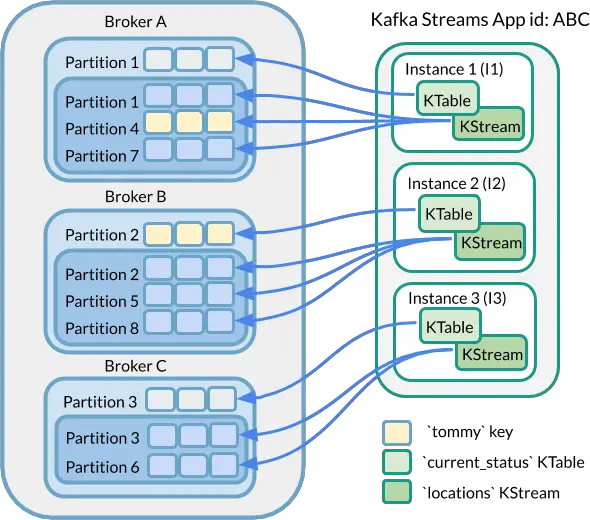
Another way to describe this scenario is to flip-the-script and ask “are there any requirements when performing joins in Kafka Streams?”. The answer, of course, is yes. And in this particular example of a KStream to KTable join, the requirement is that the data which should be joined must be “co-partitioned”. More on this available in the Resources and References section below.
How to Solve this Example Challenge?
Well, we have two options to ensure the joins will succeed regardless of which node performs the join. One of the options involve using a GlobalKTable for current_status instead of a KTable.
GlobalKTables are replicate all underlying topic partitions on each instance of KafkaStreams. So, when we modify our example to use a GlobalKTable, the tommykey event will be all 3 Kafka Stream nodes. This means a join to the locations stream will succeed regardless of which node performs the join.
Simple right? Well, like many things in software there are trade-offs.
This example doesn’t consider the size of the overall size and mutation velocity of the underlying 3 partition topic for current_status. It’s not difficult to imagine this example becoming complicated really quickly if this topic is over 10GB. That’s a lot of synchronization across nodes. That’s potentially a lot to keep in memory to avoid disk i/o.
So, in essence, whether or not GlobalKTable is a good solution depends on additional factors. But, hopefully, this post helps describe KTable vs GlobalKTable and when and why you should consider one vs the other.
By the way, the other option to GlobalKTable would be manually ensuring co-partitioning could be creating a new underlying topic(s) for either side of the join and ensuring the same number of underlying partitions AND the same partitioning strategy used. More on this approach can be found in the Resources and References section below.
Hopefully, this GlobalKTable vs KTable analysis helps. Let me know in the comments section below.
Resources and References
- Kafka Streams Join Examples
- More information on co-partitioning requirements https://docs.confluent.io/current/streams/developer-guide/dsl-api.html#join-co-partitioning-requirements
- Nice write up on GlobalKTables http://timvanlaer.be/2017-06-28/working-with-globalktables/
- Historical Perspective on adding GlobalKTables https://cwiki.apache.org/confluence/pages/viewpage.action?pageId=67633649
- To consider manually ensuring co-partitioning, see “Ensuring data co-partitioning:” section under https://kafka.apache.org/20/documentation/streams/developer-guide/dsl-api.html#join-co-partitioning-requirements
Featured Image credit https://pixabay.com/photos/back-to-nature-climate-4536617/