Apache Spark is an open-source data processing engine designed for fast and big data processing. Originally developed at the University of California, Berkeley, in 2009, as an alternative to Hadoop MapReduce batch processing framework. Spark quickly became one of the most popular frameworks in big data analytics. Spark’s main advantage lies in its ability to perform complex data processing tasks while being considerably faster than many existing tools in this field; i.e. Hadoop MapReduce paradigm.
Spark’s in-memory processing capabilities and built-in fault tolerance make it ideal for handling large volumes of data.
A key feature of Apache Spark is its versatility in programming languages which may be used when building applications built on top of it. Apache Spark supports a variety of popular programming languages including Java, Scala, Python, and R.
Spark also offers a comprehensive suite of libraries for machine learning, graph processing, and Spark stream processing, which enable it to cater to a wide range of use cases, from ETL (extract, transform, load) tasks to advanced analytics and predictive modeling.
Spark is also compatible with other big data components found in the Hadoop ecosystem which allows integration into existing data processing pipelines.
Learning and becoming productive with Apache Spark requires an understanding of a few fundamental elements. In this post, let’s explore the fundamentals or the building blocks of Apache Spark. Let’s use descriptions and real-world examples in the exploration.
The intention is for you is to understand basic Spark concepts. It assumes you are familiar with installing software and unzipping files. Later posts will deeper dive into Apache Spark and example use cases.
As mentioned, the Spark API can be called via Spark Scala, Python (PySpark) or Java. This post will use Scala, but can be easily translated to other languages and operating systems.
If you have any questions or comments, please leave a comment at the bottom of this post.
Table of Contents
- What Is Apache Spark?
- Spark Components Overview
- Spark Cluster Architecture
- Getting Started with Spark Overview
- Spark Context and Resilient Distributed Datasets
- Spark Actions and Transformations
- Conclusion and Looking Ahead
- Apache Spark Further Resources
What Is Apache Spark?
Apache Spark is an open-source, distributed computing framework designed for big data processing and analytics. As expected with a distributed compute framework, Apache Spark provides an interface for programming distributed workloads across clusters with implicit data parallelism and fault tolerance.
The distributed aspect is what can confused folks when first starting out.
Apache Spark consists of four primary components:
- Core engine: The heart of the Spark system handles task scheduling, memory management, and fault recovery. For more see Spark Core tutorials.
- Spark SQL: This component enables users to work with structured and semi-structured data using SQL queries. For more, see Spark SQL in Scala and PySpark SQL.
- Spark Streaming: With this component, Spark can handle real-time data processing, enabling users to analyze and manipulate data streams. For more see, Spark Streaming in Scala examples and tutorials.
- MLlib: A built-in machine learning library that allows developers to apply complex algorithms to data without the need for additional integrations.
Spark also comes with additional libraries such as GraphX, a graph processing library, and Cluster Manager, which is responsible for managing resources in a cluster.
Key features of Apache Spark include:
- Speed: By leveraging in-memory processing, Spark can perform up to 100 times faster than other big data processing frameworks like Hadoop’s MapReduce.
- Ease of use: Spark supports popular programming languages like Python, Java, Scala, and R.
- Flexibility: Integrates with various data sources, including Hadoop Distributed File System (HDFS), Amazon S3, and NoSQL databases like Cassandra and HBase.
Overall, Apache Spark is an efficient and powerful tool for large scale data processing and analytics and should be required learning for folks directly involved in building, managing, or planning for analytics applications.
Spark Components Overview
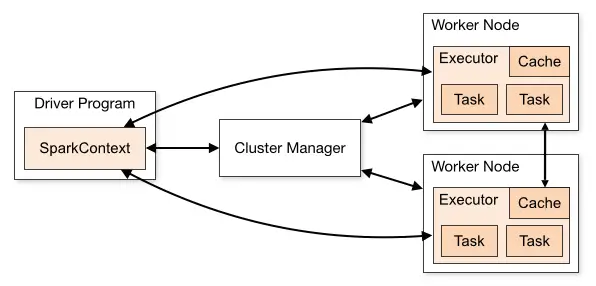
Spark applications execute as a set of independent processes on a cluster, coordinated by the SparkContext object in your primary program (called the driver program).
(Note: on newer versions of Spark (>= 2.0), you will also see use of SparkSession in lieu of SparkContext, see SparkContext vs SparkSession tutorial for more information.)
SparkContext can connect to a variety of cluster managers to operate on a cluster, including Spark’s own standalone cluster manager, Mesos, YARN, and Kubernetes. Cluster managers should be considered coordinators because they are responsible for allocation resources across applications.
Once connected, Spark acquires executors on cluster nodes called Workers, which are compute processes and may store data. Executors are segmented into units of work called Tasks.
Next, Spark dispatches your application code to the executors (defined by JAR or Python files passed to SparkContext).
Spark Cluster Architecture
At this point, a diagram will help.
Getting Started with Spark Overview
Let’s dive into code and working examples first. Then, we’ll describe Spark concepts that tie back to the source code examples.
These examples are for illustrative purposes only at this point. The examples are in Scala, but it should be straightforward enough and easily translated to Python. Again, this is just to show key concepts.
Spark with Scala Code examples
The CSV file used in the examples has following structure:
Year,First Name,County,Sex,Count
2012,DOMINIC,CAYUGA,M,6
2012,ADDISON,ONONDAGA,F,14
2012,JULIA,ONONDAGA,F,15Spark Context and Resilient Distributed Datasets
The way to interact with Spark is via a SparkContext (or as previously mentioned SparkSession in new versions of Spark). The following example uses the Spark Console (AKA: spark-shell) which provides a SparkContext automatically. Notice the last line in the following spark-shell REPL?
06:32:25 INFO SparkILoop: Created spark context.. Spark context available as sc.
That’s how we’re able to use sc from within the examples.
After obtaining a SparkContext, developers interact with Spark via Resilient Distributed Datasets or RDDs. (Update: this changes from RDDs to DataFrames and DataSets in later versions of Spark.)
Resilient Distributed Datasets (RDDs) are an immutable, distributed collection of elements. For more information on Spark RDDs, see the Spark RDD tutorial in 2 minutes or less.
Whether, RDD, DataFrame, or DataSet, the required understanding is these provide API abstractions to the underlying data itself. The data may be on a file system, object store, database, etc. and be in a variety of formats such as Parquet, Avro, JSON, CSV, Text, etc.
You may also here this data abstraction referred to as collections.
These data abstraction collections may be parallelized across a cluster; i.e. distributed across worker nodes so the Executors may perform task compute in parallel.
RDDs are loaded from an external data set or created via a SparkContext. We’ll cover both of these scenarios.
Let’s create a RDD via:
scala> val babyNames = sc.textFile("baby_names.csv")Now we have a RDD called “babyNames”.
We also created RDDs other ways as well, which we cover throughout this site as well.
When utilizing Spark, you will be doing one of two primary interactions: creating new RDDs or transforming existing RDDs to compute a result. The next section describes these two Spark interactions.
Spark Actions and Transformations
When working with a Spark RDDs, there are two available operations: actions or transformations. An action is an execution which produces a result. Examples of actions in previous are count and first.
Example of Spark Actions
babyNames.count() // number of lines in the CSV file
babyNames.first() // first line of CSVFor a more comprehensive list of Spark Actions, see the Spark Examples of Actions in Scala or Spark Examples of Actions in Python pages.
Example of Spark Transformations
Transformations may create new RDDs by using existing RDDs. We can chain and create a variety of new RDDs from babyNames:
scala> val rows = babyNames.map(line => line.split(","))
scala> val davidRows = rows.filter(row => row(1).contains("DAVID"))For a more comprehensive list of Spark Transformations, see the Spark Examples of Transformations in Scala or PySpark Examples of Transformations in Python page.
Conclusion and Looking Ahead
In this post, we covered the fundamentals for being productive with Apache Spark. As you witnessed, there are just a few Spark concepts to know before being able to be productive. What do you think of Scala? To many, the use of Scala is more intimidating than Spark itself. Sometimes choosing to use Spark is a way to bolster your Scala-fu as well.
In later posts, we’ll write and run code outside of the REPL. We’ve dive deeper into Apache Spark and pick up some more Scala along the way as well.
This tutorial has been very useful. Please continue the good work.
I think we need to separate Header row of CSV file before all above calculations
Thanks for comment! Check out other Apache Spark tutorials on this site where header row is filtered out. Example: https://supergloo.com/pyspark/apache-spark-quick-start-with-python/
Excellent . It helped me a lot to understand the basics of Spark. Thank you for taking your time and coming up with nice articles.
Excellent Tutorial…Thanks for sharing
You Made Spark very simple by this tutorial
Superb,Loban
First of all, Thanks a lot for putting together this Tutorial series!
In the reduceByKey example, the sort order is ascending. To list the name with maximum counts, the dataset needs to be sorted in descending order, by specifying a boolean value false in the second argument, as shown below:
filteredRows.map (n => (n(1), n(4).toInt)).reduceByKey((a,b) => a + b).sortBy(_._2, false).foreach(println _)
Thank you, very nice tutorial. I have one question though When i try to take distinct count i am getting ArrayIndexOutOfBoundsException for this below statement.
rows.map(row => row(2)).distinct.count
Can you please help in understanding what could be the issue ? Thanks