
Before we begin diving into event logs, let’s start with a quote from one of my software heroes.
“The idea of structuring data as a stream of events is nothing new, and it is used in many different
fields. Even though the underlying principles are often similar, the terminology is frequently
inconsistent across different fields, which can be quite confusing. Although the jargon can be
intimidating when you first encounter it, don’t let that put you off; many of the ideas are
quite simple when you get down to the core.” –Martin Kleppmann
And so begins Chapter 1 in the book “Making Sense of Stream Processing” by Martin Kleppmann.
This book can be found from numerous different sources for free
This amazingly succinct ~170-page book the best resource I’ve found for understanding the questions I had such as “Why do we need Event Logs?”, “How do we utilize Event Logs when designing Real-time Applications?”, “Are there different kinds of Event Logs?”, “Are Event Logs the same as Message Queue, Message Bus?”, etc. But before you go find the book and read it, you may wish to continue reading here.
Table of Contents
- A Personal Perspective on Event Logs
- Types of Event Logs?
- Where Event Logs?
- Without Event Log
- With Event Log
- Benefits of Event Logs in your Architecture
- Disadvantages of Event Logs
- Types of Event Logs
- Technical Differences between Event Log implementations
- Event Log Recommended Resources
A Personal Perspective on Event Logs
As a personal note, when I read this book the first time, I was challenged in designing a system that could handle a fairly large number of concurrent health-related measurement transactions. Think measurements such as weight, food intake, exercise completed, etc. On one hand, the system needed to handle these transactions as fast and as efficiently as possible. On the other hand, the system needed to aggregate and filter these transactions into composite views such as “How many individuals, with one or more kinds of certain attributes, have recorded their weight in the last 30 minutes.?”. For example, “how many individuals who live in Kentucky and work at a company called Bourbon, Inc. have eaten more than 2000 calories today?”
Answering these types of questions by querying the database where these transactions were recorded wasn’t fast enough. Extracting this transactional data from the operational data store and loading it into an analytic store wasn’t fast enough either.
But, back to the book. This book completely opened my eyes to ways I could have designed the previously mentioned architecture. If you have struggled with anything similar, then this book is the place to start. As mentioned, it can be found for free. Go get it and read it. Heck, you only have to skim Chapters 1 and 2 to get value and determine if you want to go deeper. Chapter 3 provides more information on Change Data Capture, which we covered here before.
Types of Event Logs?
Now, I know some of you are asking. Are Event Logs and Message Queue the same thing? What about the differences between an Event Log and Message Bus? Is he thinking something like Apache Kafka, Amazon Kinesis, Google Pub/Sub, Azure Event Hubs?
If you are asking these questions, the short answer is yes-and-no. For this post, the differences are not as important as the concept of an Event Log. Let’s cover differences in other posts. If there are any particular areas you’d like to cover, let me know in the comments below.
Even the “Making Sense of Stream Processing” book deflects questions such as these when Martin writes, “If you want to get a bit more sophisticated, you can introduce an event stream, or a message queue, or an event log (or whatever you want to call it).”
As we get deeper into Streaming Data Engineering use cases, we can cover more of the differences between Event Logs in other places on this site. For example, keep this in mind from the book’s Foreword.
“Whenever people are excited about an idea or technology, they come up with buzzwords to describe it. Perhaps you have come across some of the following terms, and wondered what they are about: “stream processing”, “event sourcing”, “CQRS”, “reactive”, and “complex event processing.
Sometimes, such self-important buzzwords are just smoke and mirrors, invented by companies that want to sell you their solutions. But sometimes, they contain a kernel of wisdom that can really help us design better systems.” -Neha Narkhede
Where Event Logs?
For discussion purposes and to help engrain it in my brain as well, let’s explore some diagrams.
An Application Before Event Logs (Micro Level)
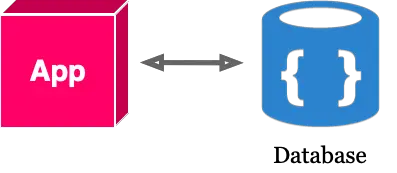
Now, “application” (App) is intentionally left vague here. At this point, it’s perfectly fine to consider this application to be a Web application or a micro-service or Log Collection agent or an IoT device.
An Application After Event Logs (again, Micro Level)
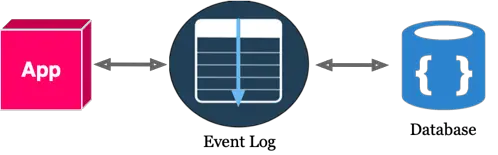
What are your initial reactions to these two diagrams now?
Does the first, “Without Event Log” diagram look faster and more straight forward? Or does the second diagram with an Event Log looks more complicated? At this point, we’re not sure of the added benefits, right?
There was a time when I couldn’t disagree with you, but then I faced the experience described above. So, let’s take a look at what happens to these diagrams when we move to less isolated scenarios. (I could have said, “let’s look at the big picture” here, but I didn’t feel like saying it that way, and this is my blog. I get to call the shots around here. I’m the Big blog bossman.)
Anyhow, let’s get back to the diagrams.
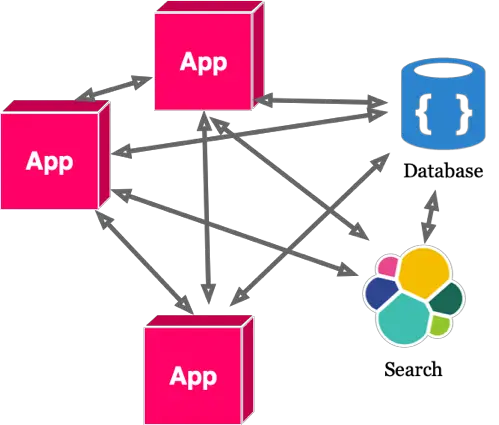
Over time, when more components require data integration, these diagrams evolve to:
Without Event Log
With Event Log
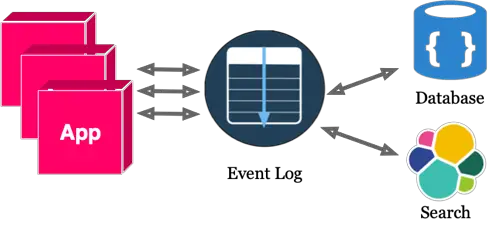
Now, which looks better?
“With an Event Log 2” diagram looks cleaner to me.
But, let’s continue looking ahead to the inevitable time with our architecture must change.
For example, what if I want to perform some calculations such as aggregations, categorizing, filtering, alerting as transaction Events occur within the system. Well, with an event log in place and the integration components decoupled, we can add a stream processor.
Adaptability to change is another benefit to utilizing the Event Log. In addition to adding Stream Processors, what happens if we want to integrate a SaaS application data down the line? Well, we could simply hang it off our Event Log.
For example, notice Stream Processing and an additional SaaS component integration in the following diagram.
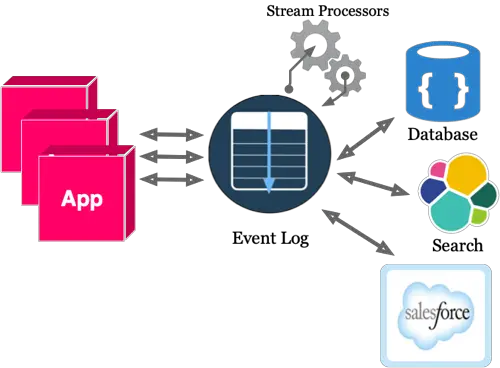
(By the way, why stream processors are covered in a different post.)
At this point, I’ll assume you are visually sold on the concept of the Event Log, or at least interested in exploring more. Let’s list further considerations, such as Benefits, Disadvantages, Types, and Technical Differences. (Let me know if you have something to add in the following lists, by the way.)
Benefits of Event Logs in your Architecture
- Loosely Coupled Integration
- Flexible, adaptable, resilient to architectural change of requirements
- Planning for Failure — some Event Logs are configurable to handle failures in nodes and networks gracefully
- Events are replayable; i.e. want to retrain a model
- Events are processed in a guaranteed order
- Foundation for real-time processing (or as close as possible to it) with Stream Processors
- Consistency
Disadvantages of Event Logs
- May seem more complicated and overkill at first
- Likely introduces a change into your architecture and way of thinking and change can be challenging
Types of Event Logs
- Apache Kafka, Apache Pulsar
- Message Queues (RabbitMQ, ActiveMQ, MQSeries, etc.)
- Cloud-Native (Kinesis, Pub/Sub, Event Hubs, Confluent)
Technical Differences between Event Log implementations
There are technical trade-offs in your choice of Event Logs including
- Producer / Consumer decoupling; i.e., multiple consumers of the same event and different points of time
- Scaleability; how many and how fast can events be processed?
- Replayability (ability to replay events for a particular point in time)
- Support for Transactions
- Exactly Once Processing
- Resiliency — Ability to set the replication factor of events and the level of acknowledgment required for appends to be considered successful.
- Out-of-the-box connectors for ingress and egress
Event Log Recommended Resources
- Start with “Making Sense of Stream Processing” by Martin Kleppmann. Search for it. You can find it for free from multiple sources at the time of this writing
- Then, move to Martin’s next book “Designing Data-Intensive Applications”
Featured Image https://pixabay.com/photos/batch-dry-firewood-forestry-logs-1868104/