
Scheduling in Spark can be a confusing topic. When someone says “scheduling” in Spark, do they mean scheduling applications running on the same cluster? Or, do they mean the internal scheduling of Spark tasks within the Spark application? So, before we cover an example of utilizing the Spark FAIR Scheduler, let’s make sure we’re on the same page in regards to Spark scheduling.
In this Spark Fair Scheduler tutorial, we’re going to cover an example of how we schedule certain processing within our application with higher priority and potentially more resources.
What is the Spark FAIR Scheduler?
By default, Spark’s internal scheduler runs jobs in FIFO fashion. When we use the term “jobs” in describing the default scheduler, we are referring to internal Spark jobs within the Spark application. The use of the word “jobs” is often intermingled between a Spark application a Spark job. But, applications vs jobs are two very different constructs. “Oyy yoy yoy” as my grandma used to say when things became more complicated. Sometimes it’s difficult to translate Spark terminology sometimes. We are talking about jobs in this post.
Anyhow, as we know, jobs are divided into stages and the first job gets priority on all available resources. Then, the second job gets priority, etc. As a visual review, the following diagram shows what we mean by jobs and stages.
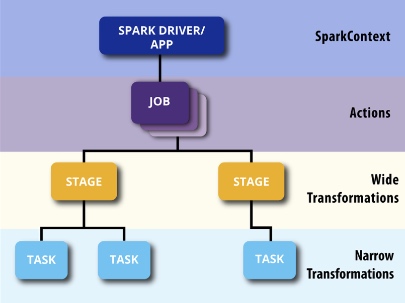
Notice how there are multiple jobs. We know this because the “Jobs” tab in the Spark UI as well.
If the jobs at the head of the queue are long-running, then later jobs may be delayed significantly.
This is where the Spark FAIR scheduler comes in…
The FAIR scheduler supports the grouping of jobs into pools. It also allows setting different scheduling options (e.g. weight) for each pool. This can be useful to create high priority pools for some jobs vs others. This approach is modeled after the Hadoop Fair Scheduler.
How do we utilize the Spark FAIR Scheduler?
Let’s run through an example of configuring and implementing the Spark FAIR Scheduler. The following are the steps we will take
- Run a simple Spark Application and review the Spark UI History Server
- Create a new Spark FAIR Scheduler pool in an external XML file
- Set the `spark.scheduler.pool` to the pool created in external XML file
- Update code to use threads to trigger use of FAIR pools and rebuild
- Re-deploy the Spark Application with
- `spark.scheduler.mode` configuration variable to FAIR
- `spark.scheduler.allocation.file` configuration variable to point to the XML file
- Run and review Spark UI History Server
Here’s a screen case of me running through all these steps
Also, for more context, I’ve outlined all the steps below.
Run a simple Spark Application with default FIFO settings
In this tutorial on Spark FAIR scheduling, we’re going to use a simple Spark application. The code reads in a bunch of CSV files about 850MB and calls a `count` and prints out values. In the screencast above, I was able to verify the use of pools in the regular Spark UI but if you are using a simple Spark application to verify and it completes you may want to utilize the Spark History Server to monitor metrics. (By the way, see the Spark Performance Monitor with History Server tutorial for more information on History Server).
Create a new Spark FAIR Scheduler pool
There is more than one way to create FAIR pools. In this example, we will create a new file with the following content
<?xml version="1.0"?>
<allocations>
<pool name="fair_pool">
<schedulingMode>FAIR</schedulingMode>
<weight>2</weight>
<minShare>4</minShare>
</pool>
<pool name="a_different_pool">
<schedulingMode>FIFO</schedulingMode>
<weight>1</weight>
<minShare>2</minShare>
</pool>
</allocations>Save this file to the file system so we can reference it later.
A note about the file options. Hopefully obvious, but we configure pools in the `pool` nodes and give it a name. Then we have three options for each pool:
- `schedulingMode` — which is either FAIR or FIFO
- `weight` — Controls this pool’s share of the cluster relative to other pools. Pools have a weight of 1 by default. Giving a specific pool a weight of 2, for example, it will get 2x more resources as other active pools
- `minShare` — Pools can be set a minimum share of CPU cores to allocate
Update code to utilize the new FAIR POOls
The code in use can be found on my work-in-progress Spark 2 repo
Set Scheduler Configuration During Spark-Submit
We’re going to add two configuration variables when we re-run our application:
- `spark.scheduler.mode` configuration variable to FAIR
- `spark.scheduler.allocation.file` configuration variable to point to the previously created XML file
Verify Pools are being utilized
Let’s go back to the Spark UI and review while the updated application with new spark-submit configuration variables is running. We can now see the pools are in use! Just in case you had any doubt along the way, I did believe we could do it. Never doubted it.
Conclusion
I hope this simple tutorial on using the Spark FAIR Scheduler was helpful. If you have any questions or suggestions, please let me know in the comments section below.
Further reference
- Spark Scheduling Docs http://spark.apache.org/docs/latest/job-scheduling.html#scheduling-within-an-application
- Spark Continuous Application with FAIR Scheduler presentation https://www.youtube.com/watch?v=oXwOQKXo9VE <- good stuff
- Spark Monitoring Tutorials
Featured image credit https://flic.kr/p/qejeR3
I have read some spark source code, I found that the SchedulingMode is initialized in TaskScheduler. So , as you write in the github , when SparkContext has been initialized , does it make any effect on SchedulingMode?It means that the SchedulingMode can be changed any time when application is running? Thanks!
Is the property spark.scheduler.allocation.file passed using –conf in launching spark-submit? Also I have another question, can the XML file be located at HDFS in such a way we can specify the property spark.scheduler.allocation.file the HDFS path? just like
–conf spark.scheduler.allocation.file=”hdfs://……”
Thanks in advance