
Apache Spark broadcast variables are available to all nodes in the cluster. They are used to cache a value in memory on all nodes, so it can be efficiently accessed by tasks running on those nodes.
For example, broadcast variables are useful with large values needing to be used in each Spark task.
By using a broadcast variable, you can avoid having to send the value to each task over the network, which can improve the performance of your Spark job.
Broadcast variables are read-only and cannot be modified once created.
Instead, if you need to update the value of a broadcast variable, new broadcast variable will need to be created and referenced instead.
The code examples in this tutorial assume you know PySpark Dataframes and how to join in PySpark and join in Spark Scala.
Table of Contents
- How to create and use a Spark broadcast variable in PySpark
- How to create and use a Spark broadcast variable in Spark with Scala
- Why use Spark Broadcast Variables?
- What are the Possible Performance Concerns when using Spark Broadcast Variables?
- What are Spark Broadcast Variable Alternatives?
- Spark Broadcast Further Resources
- Before you go
How to create and use a Spark broadcast variable in PySpark
>>> from pyspark.sql.functions import broadcast
>>> lookup = [(1, 'apple'), (2, 'banana'), (3, 'cherry')]
>>> lookup_col = ["id", "type"]
>>> lookup_table_df = spark.createDataFrame(data=lookup, schema=lookup_col)
# Create and broadcast variable
>>> broadcast(lookup_table_df)
DataFrame[id: bigint, type: string]
# Use the broadcast variable in a Spark DataFrame to join in DataFrame
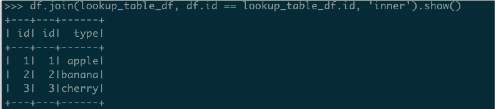
>>> df.join(lookup_table_df, df.id == lookup_table_df.id, 'inner').show()This will produce the following result
How to create and use a Spark broadcast variable in Spark with Scala
scala> val df1 = spark.createDataFrame(Seq((1, "Alice"), (2, "Bob"), (3, "Charlie"))).toDF("id", "name")
df1: org.apache.spark.sql.DataFrame = [id: int, name: string]
scala> val df2 = sc.broadcast((Seq((1, 25), (2, 30), (3, 35))).toDF("id", "age"))
df2: org.apache.spark.broadcast.Broadcast[org.apache.spark.sql.DataFrame] = Broadcast(0)
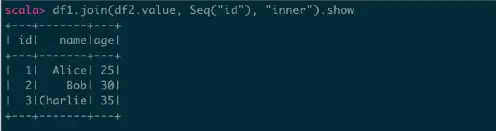
scala> df1.join(df2.value, Seq("id"), "inner").showThis will produce the following result:
Why use Spark Broadcast Variables?
There are several reasons why you might want to use broadcast variables in Apache Spark:
Improved performance: By using a broadcast variable, you can avoid having to send a large value to each task over the network. This can improve the performance of your Spark job.
For example, as shown in the above code, a lookup table is a good candidate for broadcast variable.
Shared state: Broadcast variables allow you to share state across all nodes in the cluster. This can be useful if you need to maintain a consistent view of a value across all tasks.
Ease of use: As shown above, broadcast variables are easy to use and can be accessed like any other variable in Spark. This can make it simpler to write and maintain Spark jobs that require shared state.
What are the Possible Performance Concerns when using Spark Broadcast Variables?
Yes, there are a few potential concerns to keep in mind when using broadcast variables in Apache Spark:
Memory usage: Broadcast variables are stored in memory on each node in the cluster. Make sure you have enough memory available to store the broadcast variable.
Serialization: Broadcast variables are serialized and sent to each node in the cluster, so an efficient serialization format is essential. You can specify a different serialization library (such as Kryo) to improve performance.
Network traffic: If you are using a large broadcast variable, it can take time and network bandwidth to distribute it to all Spark nodes.
Read-only: As previously mentioned, broadcast variables are read-only, so you cannot modify them once they have been created. If you need to update the value of a broadcast variable, create a new broadcast variable and use that instead.
This can be inconvenient if you need to update the value of a broadcast variable frequently.
What are Spark Broadcast Variable Alternatives?
For caching and data sharing across many Spark applications or clusters, distributed caches like Redis or Apache Ignite can be used as an alternative to Spark broadcast variables.
For example, an in-memory data store called Redis is specifically made to allow caching and fast data access. It supports data structures including strings, hashes, lists, and sets and offers quick read and write performance.
The Redis connector for Spark enables you to read and write data to Redis from Spark applications, allowing you to use Redis with Spark. Redis can be used to store and share frequently used data among many Spark applications or clusters, such as reference data or lookup tables.
There is also an Ignite connector for Spark too.
The ability to scale up your caching architecture independent of your Spark cluster may be one benefit of integration.
By reducing the need to broadcast data throughout the Spark cluster, this can enhance performance and lower network traffic. On the other hand, it may add unnecessary complexity though.
Spark Broadcast Further Resources
Broadcast variables are included in a dedicated section in the Spark Tuning Guide.
Before you go
There are many Spark Scala tutorials and PySpark SQL tutorials on this site which you find interesting.