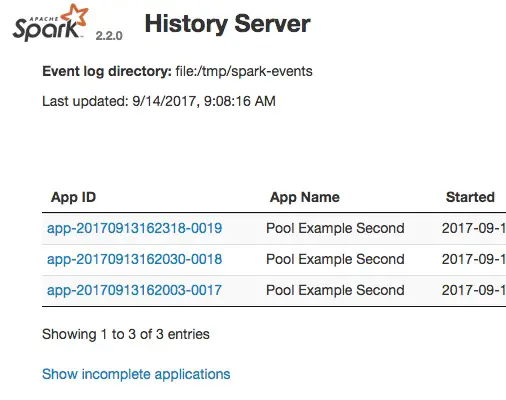
In this Apache Spark History Server tutorial, we will explore the performance monitoring benefits when using the Spark History server. This Spark tutorial will review a simple Spark application without the History server and then revisit the same Spark app with the History server. We will explore all the necessary steps to configure Spark History server for measuring performance metrics. At the end of this post, there is a screencast of me going through all the tutorial steps.
This Spark Performance tutorial is part of the Spark Monitoring tutorial series.
Table of Contents
- What is the Spark History Server?
- Spark History Server Tutorial Overview
- Step 4 Start Spark History Server
- Spark Performance with Spark History Server Conclusion
- Spark History Server Further Resources
What is the Spark History Server?
The Spark History server allows us to review Spark application metrics after the application has completed. Without the History Server, the only way to obtain performance metrics is through the Spark UI while the application is running. Don’t worry if this doesn’t make sense yet. I’m going to show you in examples below.
The Spark History server is bundled with Apache Spark distributions by default. The steps we take to configure and run it in this tutorial should be applicable to various distributions.
Spark History Server Tutorial Overview
In this spark tutorial on performance metrics with Spark History Server, we will run through the following steps:
- Run a Spark application without History Server
- Review Spark UI
- Update Spark configuration to enable History Server
- Start History Server
- Re-run Spark application
- Review Performance Metrics in History Server
- Boogie
Step 1 Spark App without History
To start, we’re going to run a simple example in a default Spark 2 cluster. The Spark app example is based on a Spark 2 github repo found here https://github.com/tmcgrath/spark-2. But the Spark application really doesn’t matter. It can be anything that we run to show a before and after perspective.
This will give us a “before” picture. Or, in other words, this will show what your life is like without the History server. To run, this Spark app, clone the repo and run `sbt assembly` to build the Spark deployable jar. If you have any questions on how to do this, leave a comment at the bottom of this page. Again, the screencast below might answer questions you might have as well.
The entire `spark-submit` command I run in this example is:
`spark-submit –class com.supergloo.Skeleton –master spark://tmcgrath-rmbp15.local:7077 ./target/scala-2.11/spark-2-assembly-1.0.jar`
but again, the Spark application doesn’t really matter.
Step 2 Spark UI Review
After we run the application, let’s review the Spark UI. As we will see, the application is listed under completed applications.
If we click this link, we are unable to review any performance metrics of the application. Without access to the perf metrics, we won’t be able to establish a performance monitor baseline. Also, we won’t be able to analyze areas of our code which could be improved. So, we are left with the option of guessing on how we can improve. Guessing is not an optimal place to be. Let’s use the History Server to improve our situation.
Step 3 Update Spark Configuration for History Server
Spark is not configured for the History server by default. We need to make a few changes. For this tutorial, we’re going to make the minimal amount of changes in order to highlight the History server. I’ll highlight areas which should be addressed if deploying History server in production or closer-to-a-production environment.
We’re going to update the conf/spark-defaults.conf in this tutorial. In a default Spark distro, this file is called spark-defaults.conf.template. Just copy the template file to a new file called spark-defaults.conf if you have not done so already.
Next, update 3 configuration variables
- Set `spark.eventLog.enabled` to true
- Set `spark.eventLog.dir` to a directory **
- Set `spark.history.fs.logDirectory` to a directory **
** In this example, I set the directories to a directory on my local machine. You will want to set this to a distributed file system (S3, HDFS, DSEFS, etc.) if you are enabling History server outside your local environment.
Step 4 Start Spark History Server
Consider this the easiest step in the entire tutorial. All we have to do now is run `start-history-server.sh` from your Spark `sbin` directory. It should start up in just a few seconds and you can verify by opening a web browser to http://localhost:18080/
The most common error is the events directory not being available. If you discover any issues during history server startup, verify the events log directory is available.
Step 5 Rerun the Spark Application
Ok, this should be another easy one. Let’s just rerun the Spark app from Step 1. There is no need to rebuild or change how we deployed because we updated default configuration in the spark-defaults.conf file previously. So now we’re all set, so let’s just re-run it.
Step 6 Review Spark Application Performance metrics in Spark History Server
Alright, the moment of truth…. drum roll, please…
Refresh the http://localhost:18080/ and you will see the completed application. Click around you history-server-running-person-of-the-world you! You now are able to review the Spark application’s performance metrics even though it has completed.
Step 7 Boogie Down
That’s right. Let’s boogie down. This means, let’s dance and celebrate. Now, don’t celebrate like you just won the lottery… don’t celebrate that much! But a little dance and a little celebration cannot hurt. Yell “whoooo hoooo” if you are unable to do a little dance. If you can’t dance or yell a bit, then I don’t know what to tell you bud.
In any case, as you can now see your Spark History server, you’re now able to review Spark performance metrics of a completed application. And just in case you forgot, you were not able to do this before. But now you can. Slap yourself on the back kid.
Spark Performance with Spark History Server Conclusion
I hope this Spark tutorial on performance monitoring with History Server was helpful. See the screencast below in case you have any questions. If you still have questions, let me know in the comments section below.
Spark History Server Further Resources
- For a more comprehensive list of all the Spark History configuration options, see Spark History Server configuration options
- Speaking of Spark Performance Monitoring and maybe even debugging, you might be interested in Spark Scala with IntelliJ tutorial or Debug Scala Spark in IntelliJ tutorial
- For more on Apache Spark
Spark History Server Screencast
Can’t get enough of my Spark tutorials? Well, if so, the following is a screencast of me running through most of the steps above