
A schema registry in data streaming use cases such as micro-service integration, streaming ETL, event driven architectures, log ingest stream processing, etc., is not a requirement, but there are numerous reasons for implementing one. The reasoning for schema registries in data streaming architectures are plentiful and have been covered extensively already. I’ve included some of my favorite resources are listed in the Resources section below. For the purpose of setting up the context for the rest of this article, I summarize the reasons why to use a schema registry here.
Table of Contents
- Why use a Schema Registry in a streaming application?
- Are there different Schema Registries available?
- Core Schema Registry Functionality? Or what do Schema Registries have in common?
- How do Schema Registries compare?
- When and how are schemas enforced?
- Are any of these Schema Registries ever used outside of Kafka?
- Why choose one over another?
- How difficult is it to switch Schema Registries?
- What’s wrong with this evaluation?
- Schema Registry Resources
Why use a Schema Registry in a streaming application?
- Better use of resources — waste lots of memory, network bandwidth and disk space if had to include the schema in every event.
- Operational Evolution — things change, fashion changes, people change, hairstyles change, and so do our definition of data through schemas. Attributes which define an Event such as an Address or an Order or a Click evolve. Fields are added or removed. Field types originally defined as a String are changed to an Int. Conceptually, this isn’t different from what many of us experienced in the traditional RDBMS database world and other purpose built databases. The term “data drift” is occasionally use to describe the concept which I think is a pretty smooth way of defining the evolution. How will the proposed change in the schema affect consumers? Will they break and be forced to change? How do we retain backwards compatibility in order to provide consumers time to change? How long do we maintain it? No real surprise here. These are examples of questions which come up after something has been deployed to production.
As we can see, there are good reasons for implementing a schema registry. No original reasoning in my thinking here. It’s a subject which has been extensively covered before, but now we have some context. At this point, we have answers for why, but as you might suspect, this leads to many more questions such as:
- Are there different Schema Registries available?
- If there are different options, how do you evaluate one vs. another? what are the factors to consider?
- Are schema registries ever used without an Event Log like Kafka or Kinesis?
- How do we enforce, manage, version police the adherence, monitor?
- How to integrate with all the components in our stack?
- How difficult is it to switch Schema Registries?
So, as we can see, once we get pass the “Why?” question, there are many follow-on questions. Let’s explore this in this post.
Are there different Schema Registries available?
By far and away, the most widely known option is the Confluent Schema Registry. But, one of the things I’ve noticed in my journey so far is many folks do not know there are a few different options for Schema Registries in Streaming applications.
Confluent’s Schema Registry is available at https://github.com/confluentinc/schema-registry under the Confluent Community License.
But, many are surprised to learn of others including:
RedHat’s Apicurio Registry available at https://github.com/apicurio/apicurio-registry
Cloudera’s Registry at https://github.com/hortonworks/registry but this doesn’t look to have any recent activity, so I won’t include much about it any further.
Aiven sponsored Karaspace at https://karapace.io/ which is self-described as “a 1-to-1 replacement for Confluent’s Schema Registry and Apache Kafka REST proxy”.
AWS provides Glue Schema Registry with more information available here https://docs.aws.amazon.com/glue/latest/dg/schema-registry.html and in the client available https://github.com/awslabs/aws-glue-schema-registry
Last time I checked, this was the entire list of Schema Registries, but let me know if I’m missing any!
Core Schema Registry Functionality? Or what do Schema Registries have in common?
All store schemas and all can store different versions of the same schema; think a new version when a schema is updated with a new field. Schema registries use different versions for compatibility checking as a schema changes over time.
Schema registries have schema compatibility checking options based on certain rules like NONE, BACKWARD, FORWARD, FULL, etc. These rules are used when the connector observes schema changes and a desired outcome.
See https://docs.confluent.io/platform/current/schema-registry/avro.html#compatibility-types for a summary table of schema changes allowed for the different compatibility types
How do Schema Registries compare?
Now, that we know there are different options for deploying a Schema Registry for streaming, let’s explore the pros and cons of each one. The most efficient way to do list is in a comparison table.
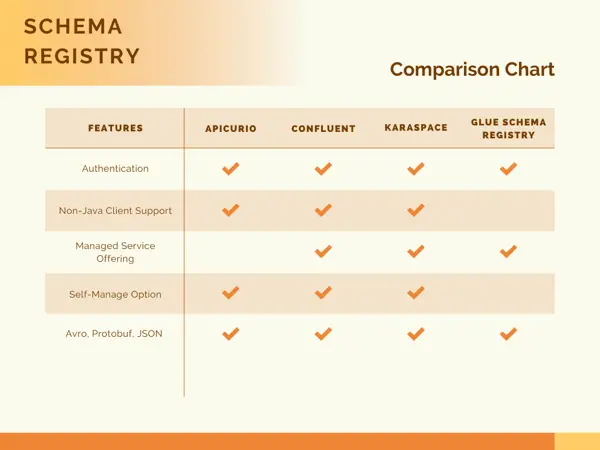
In addition to the current list of features and capabilities listed above, it will be helpful to get sense of each projects “Github Pulse” to indicate recent activity and potential future trajectory.
I was going to list some stats for each on of these projects, but that will surely change over time. So, instead of me listing here, follow the links above and click on the Insights tab.
When and how are schemas enforced?
Schema checking are optional on the client and not the broker except for Confluent has a broker side option. Here’s how Pulsar describes it
Applications typically adopt one of two basic approaches to type safety in messaging with schema registries:
- On the producer or consumer “client-side” when serializing and deserializing messages. Enforcing the use of a schema registry on the client side is not possible, which often leads to the next approach.
- A “server-side” approach in which streaming event log such as Kafka or Kinesis checks and attempts to enforce schema adherence. Unlike the previous “client-side” approach, this schema check cannot be bypassed. Proprietary Confluent offering is the only Kafka or Kinesis based option I know of that can choose this approach. There are pros and cons with this approach.
Are any of these Schema Registries ever used outside of Kafka?
From my perspective, the answer is rarely. I occasionally see them used with Kinesis.
Why choose one over another?
As you can see from comparison table above, there are not many compelling differences. A couple of reasons could come down to the license of the registry, or whether or not utilizing a managed service vs. self-managed, or whether or not proprietary vs open source matters to you.
How difficult is it to switch Schema Registries?
Change out the client library on your producers and consumers and migrate existing is what you might be thinking. But, I strongly suspect the SerDe used in the original Kafka message will make things really difficult if you need to read older messages during the migration. Each Schema Registry has SerDe library which determines how/where the associated schema for a message is stored; i.e. Confluent’s is stored bytes 1-4 in the message.
I know Glue Schema Registry provides an option to help migrate through the ability to specific two schema registries in the client. See https://docs.aws.amazon.com/glue/latest/dg/schema-registry-integrations-migration.html for more.
Apicurio has a `ENABLE_CONFLUENT_ID_HANDLER` variable which can be set in their client library SerDe configuration. This appears designed to aid in schema registry migrations.
Since Karaspace attempts to be a drop-in replacement for Confluent Schema Registry, I’m betting the migration path is just ensuring Karaspace is using the original storage topic that Confluent Schema Registry was using; i.e. the _schemas topic.
I’m unaware of any other tooling or options to help migrate from one to the other.
What’s wrong with this evaluation?
There are few things about this evaluation that I did not include. I am open to hearing your feedback and suggestions.
- I know someone is going to call out that I didn’t include Pulsar Schema Registry and they will be 100% correct. I didn’t. It appears it is Pulsar specific. But also, I hope to spend more time with Pulsar in the future and I plan to include more exploration of Pulsar Schema Registry then.
- I didn’t include anything related to CloudEvents spec and in particular the Schema Registry spec. More info here https://github.com/cloudevents/spec/blob/main/schemaregistry/spec.md
Other than that, I don’t think I’m missing anything obvious, but again, I would appreciate feedback. My gut tells me that Confluent Schema Registry probably has a leg up on the other schema registries for certain edge cases; i.e. is it possible to set value.subject.name.strategy to io.confluent.kafka.serializers.subject.TopicRecordNameStrategy with schema registries other than Confluent’s? Others?
Schema Registry Resources
- An origin story of Confluent Schema Registry — https://issues.apache.org/jira/browse/AVRO-1124
Image credit https://pixabay.com/photos/izmailovo-the-izmailovo-kremlin-5349461/