
Running spark submit to deploy your application to an Apache Spark Cluster is a required step towards Apache Spark proficiency. As covered elsewhere on this site, Spark can use a variety of orchestration components used in spark submit command deploys such as YARN-based Spark Cluster running in Cloudera, Hortonworks or MapR or even Kubernetes.
There are numerous options for running a Spark Cluster in Amazon, Google or Azure as well. But, running a standalone cluster on its own is a great way to understand some of the mechanics of Spark Clusters.
In this post, let’s start understanding our Spark cluster options by running a Spark cluster on a local machine. Running a local cluster is called “standalone” mode.
This will provide the environment to deploy examples of both Python and Scala examples to the Spark cluster using spark-submit command.
If you are new to Apache Spark or want to learn more, you are encouraged to check out the Spark with Scala tutorials or Spark with Python tutorials.
Table of Contents
- Spark Cluster Standalone Setup
- Running a Spark Cluster Standalone Steps
- How to Deploy with Spark Submit Command
- Spark Submit Conclusion
Spark Cluster Standalone Setup
To truly understand and appreciate using the spark-submit command, we are going to setup a Spark cluster running in your local environment. This is a beginner tutorial, so we will keep things simple. Let’s build up some momentum and confidence before proceeding to more advanced topics.
- This tutorial assumes and requires you have already downloaded Apache Spark from http://spark.apache.org
- After download, expand the downloaded file (unzipped, untarred, etc.) into a directory in your environment.
- Finally, it assumes you have opened a terminal or command-prompt and are the root of the downloaded and Spark directory.
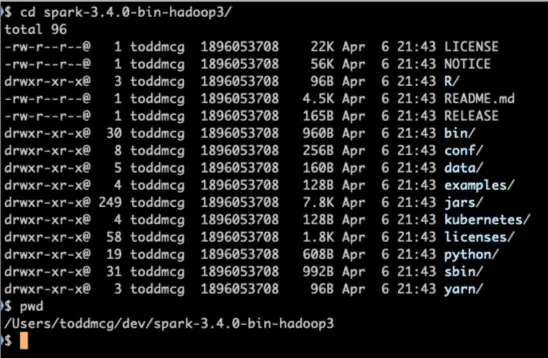
For example, I have downloaded Apache Spark 3.4.0 tgz file from Apache mirror site, extracted this file into a folder called “dev” and then proceeded to enter the directory in a shell as seen in the following screenshot.
Running a Spark Cluster Standalone Steps
Let’s begin
1. Start the Spark Master from your command prompt
./sbin/start-master.shYou will see something similar to the following:
$ ./sbin/start-master.sh
starting org.apache.spark.deploy.master.Master, logging to /dev/spark-3.4.0-bin-hadoop3/logs/spark-toddmcg-org.apache.spark.deploy.master.Master-1-3c22fb66.com.outYou should now be able to load the Spark UI at http://localhost:8080:
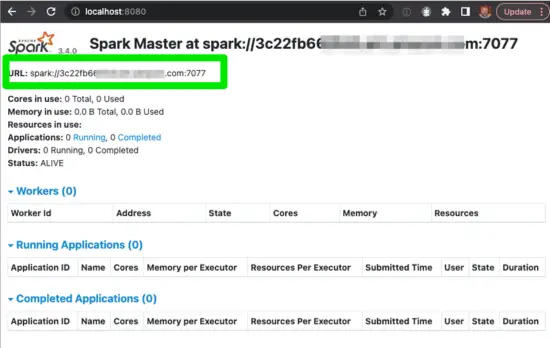
As a quick refresher, the Spark Application Master is responsible for brokering resource requests by finding a suitable set of workers to run the Spark applications.
Note: the green box contains the spark URL you required in next step.
2. Start a Spark Worker using start-worker.sh and passing in the Spark Master from the previous step (hint: the green box)
// hostname changed to protect the innocent $ ./sbin/start-worker.sh spark://3c22fb66.com:7077
Next, verify the Worker by viewing http://localhost:8080 again. You should see the worker:
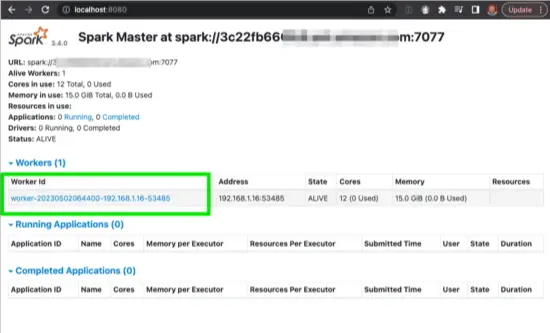
Recall, Spark Workers are responsible for processing requests sent from the Spark Master.
3. Now, let’s connect with the spark-shell REPL to the Spark Cluster
$ ./bin/spark-shell spark://3c22fb660.com:7077If all goes well, you should see something similar to the following:
Setting default log level to "WARN".
To adjust logging level use sc.setLogLevel(newLevel). For SparkR, use setLogLevel(newLevel).
23/05/02 07:36:47 WARN NativeCodeLoader: Unable to load native-hadoop library for your platform... using builtin-java classes where applicable
Spark context Web UI available at http://192.168.1.16:4040
Spark context available as 'sc' (master = local[*], app id = local-1683031008286).
Spark session available as 'spark'.
Welcome to
____ __
/ __/__ ___ _____/ /__
_\ \/ _ \/ _ `/ __/ '_/
/___/ .__/\_,_/_/ /_/\_\ version 3.4.0
/_/
Using Scala version 2.12.17 (OpenJDK 64-Bit Server VM, Java 16.0.2)
Type in expressions to have them evaluated.
Type :help for more information.
scala>If you have reached this point successfully, you have verified your local Spark cluster is ready for application deployment using Spark submit command spark-submit.sh.
At this point you can exit the shell, by issuing ctrl-D or :quit as shown
scala> :quit
$Let’s explore that next.
How to Deploy with Spark Submit Command
How do you deploy a Scala program to a Spark Cluster? In this tutorial, we’ll cover how to build, deploy and run a Scala driver program to a Spark Cluster.
The focus will be on a simple example in order to gain confidence and set the foundation for more advanced examples in the future.
We are going to cover deploying with examples with spark-submit in both Python (PySpark) and Scala.
Spark Submit with Python Example
Apache Spark community has made it pretty easy to deploy a Python example application to an Apache Spark cluster using spark-submit.
- You are back at the shell prompt, because you exited the spark-shell as described above
- Run
bin/spark-submit --master spark://3c22fb66.com:7077 examples/src/main/python/pi.py 1000
Updating your hostname for 3c22fb66.com of course.
You’ll see some logs fly by on your screen using with INFO. Eventually, you should see something similar to “took 21.515884 s
Pi is roughly 3.148000″
While Pi is being determined, you should check the Spark UI to see the PySpark example deployed and running with the spark submit as shown here:
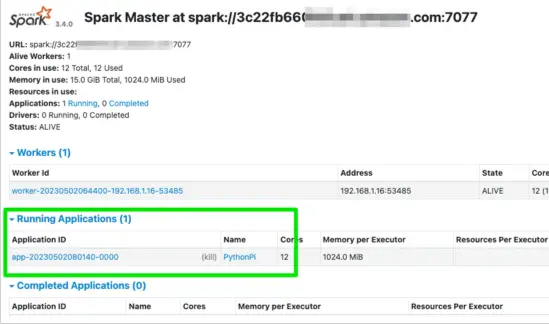
Congratulations! You deployed your first PySpark example with Spark Submit Command.
Spark Submit with Scala Example
As you could have probably guessed, using Spark Submit with Scala is a bit more involved. As shown to the Spark documentation, you can run a Scala example with spark submit such as the following:
$ ./bin/run-example SparkPi 10But that won’t use our local cluster. How can you tell? After running this example, check the Spark UI and you will not see a Running or Completed Application example; just the previously run PySpark example with spark submit will appear. (Also, if we open the bin/run-example script we can see the spark-submit command isn’t called with the required master argument.)
Now, we can change this if we pass in the the Spark master argument such as the following
./bin/run-example --master spark://3c22fb66:7077 SparkPi 10If we run this example, now the SparkPi example will use our cluster as verified in the Spark UI:
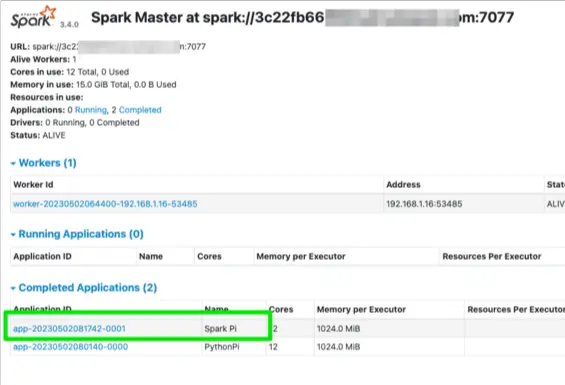
While this may be helpful, let’s make this example a bit more complicated. Feel free to skip this next section if you are interested in deploying Scala based JAR files to a Spark Cluster with spark-submit.
Spark Submit with Scala JAR Spark Cluster Setup
As this is a more advanced example, I presume you have Scala and Git experience
- You need to have SBT installed; on a Mac with homebrew
brew install sbt - In terminal, clone spark-scala-examples repo from https://github.com/supergloo/spark-scala-examples
cd spark-scala-examples- Run
sbt package
You’ll like see some log files scrolling by doing their log file thing.
When successful, you’ll have a spark-sample jar file as shown:
$ ls target/scala-2.12/
classes sync zinc
spark-sample_2.12-1.0.jar updateFor the extra curious, the Scala source code used in this SparkPi example is stolen from the Apache Spark examples distro. While having example code is important, it is also more convenient for this spark submit command tutorial.
Okey dokey, let’s use spark-submit to deploy this example.
Spark Submit Command with Jar Example
After we have built the JAR file containing the SparkPi class example, we deploy it using spark-submit.
In my environment example, this is achieved with the following:
# Just showing pwd and ls commands to explain paths used in spark-submit
$ pwd
/Users/toddmcg/dev/spark-scala-examples/spark-submit
$ ls ../../spark-3.4.0-bin-hadoop3/
LICENSE README.md conf jars logs work
NOTICE RELEASE data kubernetes python yarn
R bin examples licenses sbin
$ ~/dev/spark-3.4.0-bin-hadoop3/bin/spark-submit --class org.apache.spark.examples.SparkPi --master spark://3c22fb66.com:7077 target/scala-2.12/spark-sample_2.12-1.0.jar 100As you cna see, you’ll need to update your paths to spark-submit and spark master accordingly.
When this succeeds, you’ll now see the Spark Pi example either in Running or Completed Applications with the Spark UI:
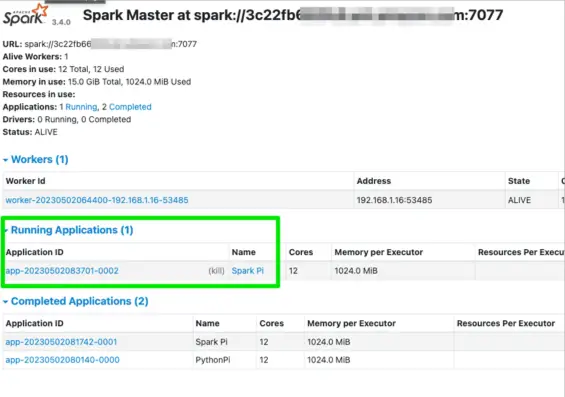
Cool, we did it. Well, I know I did it, I hope you did it too.
Spark Submit Conclusion
In this Spark Submit tutorial, we covered running a cluster in Standalone mode in your environment. Next we deployed Python and Scala examples using spark-submit command.
For those inclined, a more example of building and deploying a JAR with a Scala driver program to Spark Cluster was shown as well.
To stop your worker and master, you may use the helpful scripts as shown:
$ sbin/stop-workers.sh --master spark://3c22fb66.com:7077
localhost: stopping org.apache.spark.deploy.worker.Worker
$ sbin/stop-master.sh --master spark://3c22fb66.com:7077
stopping org.apache.spark.deploy.master.Master
Further Spark Submit Reference
- For a more detailed analysis of standalone configuration options and scripts, see https://spark.apache.org/docs/latest/spark-standalone.html#cluster-launch-scripts
- http://spark.apache.org/docs/latest/submitting-applications.html