
We choose Stream Processing as a way to process data more quickly than traditional approaches. But, how do we do Stream Processing?
Is Stream Processing different than Event Stream Processing? Why do we need it? What are a few examples of event streaming patterns? How do we implement it?
Let’s get into these questions.
As you’ve probably noticed, the topic of stream processing is becoming popular but the idea itself isn’t new at all [1]. The ways we can implement event stream processing vary, but I believe the intention is fundamentally the same. We use Event Stream Processing to perform real-time computations on data as it arrives or is changed or is deleted. Therefore, the purpose of Event Stream Processing is simple. It facilitates the real-time (or as close as we can get to real-time) processing of our data to produce faster results. It is the answer to “why we need stream processing?”.
Table of Contents
- Why do we need stream processing?
- What is not stream processing?
- What is Stream Processing?
- Stream Processor Constructs
- Stream Processing Vertical Applications
- Conclusion
Why do we need stream processing?
One way to approach the answer to this question is to consider businesses. Businesses constantly want more. They want to grow or they want to stay the same. If they want to grow, they need to change. If they want to stay the same, the world changes around them and they likely need to adapt to it and that means change. It doesn’t matter. Let’s just go with the premise that businesses constantly want more and need to change and evolve to survive.
One area where businesses want more is data processing. They want to process data faster to make money, save money or mitigate possible risks. Again, it’s simple. One way to process data faster is to implement stream processing.
What is not stream processing?
Before we attempt to answer “what is stream processing”, let’s define what it isn’t. Sound ok? Well, I hope so. Here goes…
In a galaxy far, far away, businesses processed data after it landed at various locations to produce a result. This result was computed much later than when the data originally “landed”. The canonical example is the “daily report” or the “dashboard”. Consider a daily report or dashboard which is created once per day and displays the previous business day’s sales from a particular region. Or similarly, consider determining a probability score if a credit card transaction was fraudulent or not, 5 days after the transaction(s) occurred. Another example is determining a product is out-of-stock one day after the order was placed.
There are common threads in these examples. One, the determination of the result (daily report, fraud probability score, product out-of-stock) is produced much later than when the event data used in the calculation occurred. Businesses want it to happen faster without any quality trade-offs.
Another common thread is how these determinations are implemented in software. This implementation described in these examples is referred to as “batch processing”. Why is it called “Batch”? Because of the way these example results are calculated often based on processing a group of types of data at the same time. To create a daily report, a group of the previous day’s transactions is used at 12:30a each day. In the batch processor, multiple transactions are used from beginning to end of the processing. To determine possible fraud, a group of the previous 5 days’ worth of transactions is used in the batch process. While processing a group of the previous 8 hours of order transactions (in batch), one order, in particular, is determined not available in the current inventory.
Wouldn’t it be faster to produce the desired results as the data as it is created? The answer is Yes. Yes, the report or dashboard results could be updated sooner if they were updated as each order event occurred. Yes, the fraud probability determination would be much quicker if the most recent transaction event was processed immediately after it happened. And finally, yes, the out of inventory event could be determined much more quickly if the associated order event was processed at the time it was attempted.
As you’ve probably guessed, the underlines on the word “event” above are intentional. Here is a spoiler alert. You need to process events in stream processing. That’s why stream processing is often referred to as “event stream processing”.
Stream Processing is not Batch Processing.
What is Stream Processing?
Let’s take a look at a couple of diagrams. Here’s an example of how Stream Processing may fit into an existing architecture.
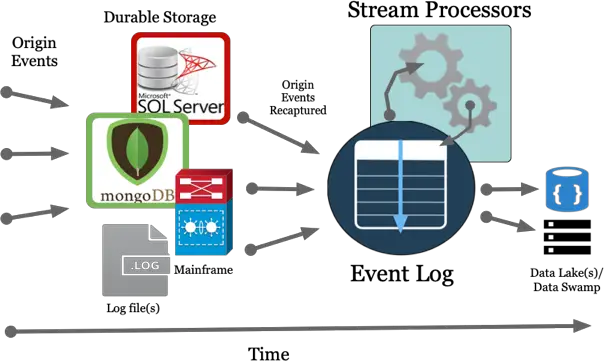
Origin events are created from downstream applications such as an E-commerce site or a green screen terminal. Events are captured and stored in various formats including RDBMS, NoSQL, Mainframes, Log files. Next, these events (inserts, updates, deletes, appends to a log file, etc.) are written into an Event Log. Now, our Stream Processor(s) can be invoked and consume data from one or more Topics in the Event Log and process these events. Processing examples include calculating counts over a specified time range, filtering, aggregating and even joining multiple streams of Topic events to enrich into new Topics. There are many tutorial examples of Stream Processors on this site.
By the way, for more information, see the post on Event Logs.
The example diagram above is ideal when implementing Stream Processing into existing architectures. The “Origin Events Recaptured”, Event Log and Stream Processors can be implemented and evolved which is beneficial for numerous reasons.
What if we are creating a brand-new, greenfield application? And what if this application includes micro-services? Stream Processors can fit nicely here as well as shown in the following diagram.
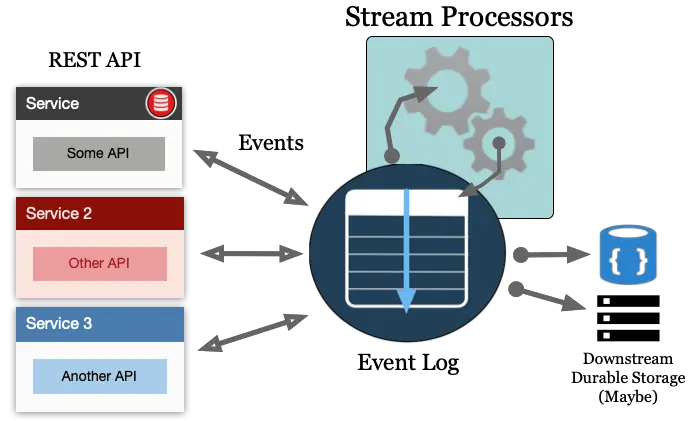
As you can see, Stream Processors can be implemented of the Event Log used in microservice architectures as well. It is important to note the changes to the arrows in this microservice example above. Notice how the arrows indicate data flow To and From the Event Log now. In this example, Stream Processors are likely creating curated or enriched data Topics that are being consumed from various micro-services and/or landed in some downstream storage such as HDFS or an object store like S3 or some type of Data Lake.
What do most businesses software architectures look like today?
If you could combine both the diagrams above into one, that is what I see as most common. Also, there are variances of these diagrams when implementing multiple data center solutions such as Hybrid Cloud.
As shown above, one key takeaway of stream processing is determining if you will or will not implement an Event Log. Because I hear some of you and yes, I guess we could build stream processors without an Event Log, but why? Seriously, let us know in the comments below.
The Event Log will be a distributed transaction, ordered, append-only log for all your streaming architectures. The Event Log is our lynchpin for building distributed, flexible streaming systems are there are various options available. But again, the log is nothing new. Again, the concept isn’t new. Many RDBMS use changelogs (or WAL “write-ahead logs”) to improve performance, provide point-in-time-recovery (PITR) hooks for disaster recovery and finally, the foundation for distributed replication.
In most cases, I believe you’ll benefit from choosing to utilize a distributed event log, but there are cases where you may wish to stream directly and checkpoint along the way. We’ll cover the Event Log in more detail in other areas of this site.
Can we Debate what a Stream Processor is Now?
I consider two requirements to be an Event Log and a Stream Processor Framework or Application. When designing stream processors, I write the stream processor computed results back to the Event Log rather than directly writing the results to a data lake or object store or database.
If results of stream processor results is required, it can be performedsomeplace else outside of the stream processor itself such as a Kafka Connect sink connector; e.g. use a Kafka Connector sink to write to S3, Kafka Connect Azure Blog Storage, Cassandra, HDFS, BigQuery, Snowflake, etc.
We have options for the implementation of our Event Log and Stream Processor compute.
Event Logs are most likely implemented in Apache Kafka, but the approach led by Apache Kafka has been expanded into other options as well.
For Stream Processors, our options include Kafka Streams, kSQLdb, Spark Streaming, Pulsar Functions, AWS Lambda, StreamSets, Nifi, Apache Beam, Databricks, Apach Flink, and older options such as Storm, Samza.
What else? What am I missing? Let me know in the comments below.
On this site, we’ll deep dive into all these implementations examples and more.
For now, check out the tutorial sections of the site
Regardless of your implementation, there are certain constructs or patterns in stream processing which we should know or at minimum, be aware of for future reference.
Stream Processor Constructs
- Stateless or Stateful – can the calcuated result by achieved by analyzing a single event? or does the result need to be calculated from considering multiple events?
- Ordering – do we need to process each event in strict order or is it perfectly fine to compute out of order in another case?
- Event time vs processing time – must consider event vs processing time, an example could be calculating the average temperature every 5 minutes or average stock price over the last 10 minutes
- Stream Processor Windows – in concert the meaning of time, perform calculations such as sums, averages, max/min. An example could be calculating the average temperature every 5 minutes or average stock price over the last 10 minutes. Related: stateful vs stateless.
- Failover and replication
- Joins – combining data from multiple sources and attempt to infer from or enrich into a new event
Stream Processing Vertical Applications
Where are Stream Processing solutions most prevalent? The short answer is everywhere. Stream processors are beneficial in healthcare, finance, security, IoT, Retail, etc. because as mentioned in the beginning, every industry wants data to be faster.
Specific solutions that span multiple verticals include:
- Refined, harmonized, filter, streaming ETL – streaming from raw to filtered; transformations; anonymization, protected
- Real-Time Inventory, Recommendations, Fraud Detection, Alerts, Real-Time XYZ, etc
- Specialized – for example, stream data to search implementations such as Elastic or Solr
- Machine Learning / AI – streaming data pipelines to training data repositories as well as running through a machine learning model(s)
- Monitoring and alerting
- Hybrid or Multi-cloud
Conclusion
Streaming Architecture will be interesting for years to come. Let’s have some fun exploring and learning.
Additional Resources
[1] The concept described above isn’t necessarily new, as you’ll see in the following example shown in SQL https://en.wikipedia.org/wiki/Event_stream_processing.
Image credit https://pixabay.com/en/seljalandsfoss-waterfall-iceland-1751463/
gRPC with Protobuf is another. I wonder why would anyone needed data streaming thru log file. If I had the logs, a partial file (or even fragmented or partitioned file) transfer would give better performance over streaming because that had to do with when to initiate streaming, the data flow degradation factor? Data streaming is best utilized with real time event data and on water marked events as needed.
Thanks Senn. For logs, I was thinking more along the lines of Apache Kafka or others. I wrote about it a bit more recently at https://supergloo.com/data-engineer/why-event-logs/ in case you’re interested. Thanks again for contributing!