
Why “Joinable” Streaming Test Data for Kafka?
When creating streaming join applications in KStreams, ksqldb, Spark, Flink, etc. with source data in Kafka, it would be convenient to generate fake data with cross-topic relationships; i.e. a customer topic and an order topic with a value attribute of customer.id. In this example, we might want to hydrate or enrich events in the order topic stream with customer topic data…. via joins.
This post will show how to generate cross-topic related events in Kafka, so you can write and test stream join code. Let’s consider it an expansion to the previous post on generating test data in Kafka. I’m going to show how to generate both Avro and JSON. You’ll have choices.
At the end of this post you will have a local running Kafka cluster in Docker with test data being delivered to multiple topics. You’ll have the ability to choose between Avro or JSON for the payload of the tests messages. At the end, you will have a convenient spot to run and test your streaming join code. Let the good times begin.
System Requirements
- Docker install and running
- docker-compose
- git
- curl
- jq
- A fun lovin, do-not-take-yourself-too-seriously, good times attitude
Assumptions
Before we begin, you should know this post assumes this isn’t your first time using Docker, docker-compose, and Git. This means you should be comfortable starting and stopping containers in your environment. Now, you may be wondering, how can I make these assumptions? Well, it’s simple, I can make these assumptions because it’s my blog and I’m the big-time boss around here.
Overview
Here’s how we’re going to do it. We’re going to run a Kafka cluster and Kafka Connect node in Docker containers with docker-compose. We’re going to use a 3rd party Kafka Connect connector called Voluble for generating the joinable test data. I’m show how to install, configure and run it our Docker containers. I’ve written about Voluble in the past. It’s awesome.
Kafka Join Test Data Setup Steps
- Start Docker if it is not already running
- Download zip file from https://www.confluent.io/hub/mdrogalis/voluble and extract. Depending on the version you downloaded, you should have a directory such as `mdrogalis-voluble-0.3.1`. In this case, I downloaded version 0.3.1.
- git clone https://github.com/conduktor/kafka-stack-docker-compose.git
- cd kafka-stack-docker-compose
- mkdir connectors && cd connectors
- Copy the directory from Step 1; i.e. `mdrogalis-voluble-0.3.1` to the
connectorsdirectory. (Remember you are in the kafka-stack-docker-compose directory which has thisconnectorsdirectory. For example, theconnectorsdirectory will have mdrogalis-voluble-0.3.1/ directory in it now. - cd .. (so you are back to the kafka-stack-docker-compose directory)
- docker-compose -f full-stack.yml up -d (this will start on the Docker containers. Give it 30 seconds or so after starting up.)
- curl http://localhost:8083/connector-plugins | jq ‘.’ (This is to confirm you can list the Kafka Connect plugins available. You should see VolubleSourceConnector in the list. You need this step to complete successfully before continuing.)
Ok, at this point, you are ready to start the Voluble Kafka Connect connector with test data.
Streaming Join Test Configuration and Start
In this example, I’m going to use an example config file at https://github.com/tmcgrath/kafka-connect-examples/tree/master/voluble/joinable.json. It’s config file to generate some joinable data. Download this file (or copy-and-paste the contents to a new file) to your environment called joinable.json.
Now, in the same directory as the joinable.json file, start the Voluble connector with
curl -X POST -H "Accept:application/json" -H "Content-Type: application/json" --data @joinable.json http://localhost:8083/connectors | jq '.'
As you can see, this assumes you have a voluble.json file in your current directory.
If the command was successful, you should see an output similar to the following
{
"name": "joinable",
"config": {
"connector.class": "io.mdrogalis.voluble.VolubleSourceConnector",
"genkp.inventory.sometimes.with": "#{Code.asin}",
"genkp.inventory.sometimes.matching": "inventory.key",
"genv.inventory.amount_in_stock.with": "#{number.number_between '5','15'}",
"genv.inventory.product_name.with": "#{Commerce.product_name}",
"genv.inventory.last_updated.with": "#{date.past '10','SECONDS'}",
"genkp.customer.with": "#{Code.isbn10}",
"genv.customer.name.with": "#{Name.full_name}",
"genv.customer.gender.with": "#{Demographic.sex}",
"genv.customer.favorite_beer.with": "#{Beer.name}",
"genv.customer.state.with": "#{Address.state}",
"genkp.order.matching": "inventory.key",
"genv.order.quantity.with": "#{number.number_between '1','5'}",
"genv.order.customer_id.matching": "customer.key",
"global.throttle.ms": "1000",
"global.history.records.max": "10000",
"name": "joinable"
},
"tasks": [],
"type": "source"
}You should now be generating test data in Avro format.
There are multiple ways to view and confirm what we just did, so I’ll briefly show a couple of different ways. At some point, I’ll probably use this example to demonstrate an Apache Flink app with Kafka Join. Let me know if you’d like to see that.
I have Kafdrop running and configured to use the Confluent Schema Registry which is running at port 8081 in the full-stack deploy we ran earlier. From Kafdrop, I can see that an order messages always reference a customertopic message key.
Order topic with customer_id set
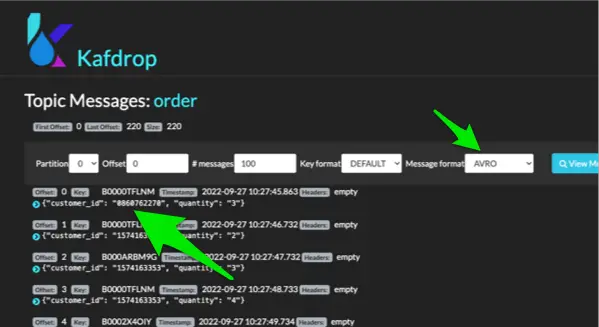
and if we compare it to the customer topic message key, we’ll see the reference. For example a customer_id of 0860762270 matches the customer key
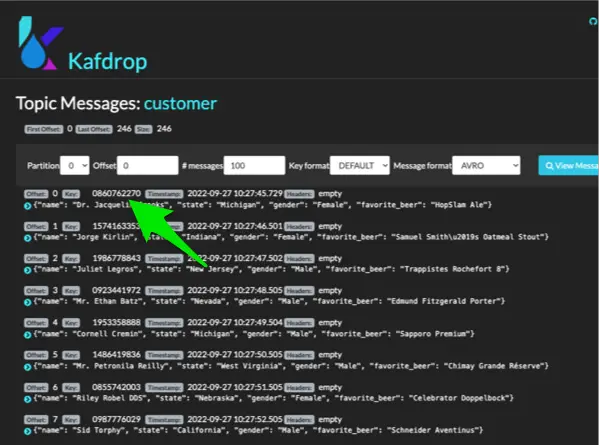
I know many of you will not have Kafkdrop installed, so you can also test with something like kcat. For example, if you run:
kcat -b localhost:9092 -t customer -s avro -r http://localhost:8081
and compare the output to
kcat -b localhost:9092 -t order -s avro -r http://localhost:8081
But both of these verification methods are a bit away from the primary focus of this post. But, if you’d like me to make a screencast video to demonstrate any of this, just let me know in comments below.
Avro and JSON Test Data Generation Examples
By default, what we did in the above steps will produce/consume messages in Avro format. This may be exactly what you are looking for. But, just in case, let’s quickly explore how we would generate JSON payload instead of Avro. There is nothing to change in Voluble. Just need to make changes to the Kafka Connect container configuration.
To generate JSON instead of Avro, open the full-stack.yml file and change the lines as shown in the following snippet
# CONNECT_KEY_CONVERTER: io.confluent.connect.avro.AvroConverter
CONNECT_KEY_CONVERTER: org.apache.kafka.connect.storage.StringConverter
# CONNECT_KEY_CONVERTER_SCHEMA_REGISTRY_URL: 'http://kafka-schema-registry:8081'
# CONNECT_VALUE_CONVERTER: io.confluent.connect.avro.AvroConverter
CONNECT_VALUE_CONVERTER: org.apache.kafka.connect.json.JsonConverter
# CONNECT_VALUE_CONVERTER_SCHEMA_REGISTRY_URL: 'http://kafka-schema-registry:8081'
CONNECT_VALUE_CONVERTER_SCHEMAS_ENABLE: "false"For those of you wondering what changed, there are new values for KEY and VALUE converters as well as a new line for CONNECT_VALUE_CONVERTER_SCHEMAS_ENABLE.
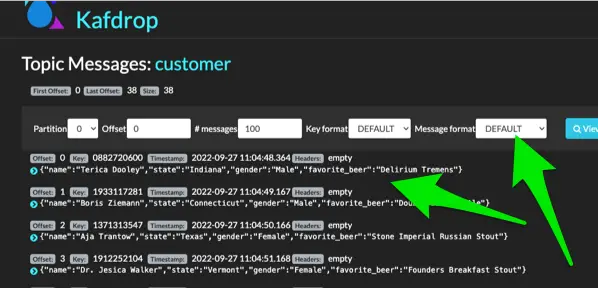
To see this in action, stop the existing containers with docker-compose -f full-stack.yml down. The previously created topics and data will not be retained.
Now, if you start at step 8 from the original setup instructions provided above and then re-POST in exact same the Voluble config, you will now produce JSON value payloads with a String key.
Looking Ahead
As mentioned in the excellent Voluble documentation, notice the references to various .matching settings in the source JSON config file for cross-topic relationships; i.e.
"genv.order.customer_id.matching": "customer.key"For even further examples of what you can do, check out Java Faker github repo. Link below.
You are now ready to point your Flink || Spark || KStreams || ksql using the topics generated and hydrated with Voluble.
Hope this helps!
Streaming Join Test Data References
- https://github.com/MichaelDrogalis/voluble
- https://github.com/tmcgrath/kafka-connect-examples/tree/master/voluble/joinable.json
- https://github.com/DiUS/java-faker
- // TODO What next? a Kafka Streams, Spark or Flink example of using this joinable test data to perform joins. I’m thinking Flink, but let me know if you have a preference.
Image credit https://pixabay.com/illustrations/texture-pixels-tile-background-2484499/